Art: Web-Artikel Original-Link: https://www.nature.com/articles/s41586-025-09422-z Veröffentlichungsdatum: 2025-02-14
Zusammenfassung #
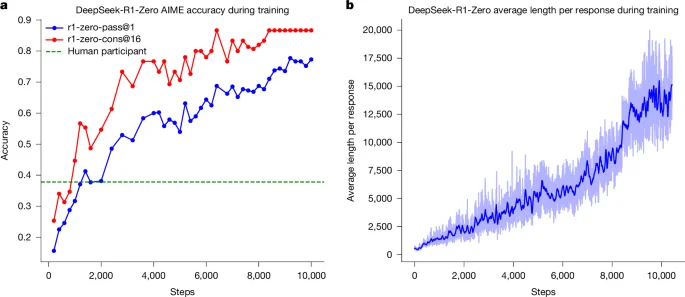
WAS - Der Artikel in Nature beschreibt DeepSeek-R1, ein KI-Modell, das Reinforcement Learning (RL) nutzt, um die Denkfähigkeiten von Large Language Models (LLMs) zu verbessern. Dieser Ansatz eliminiert die Notwendigkeit von menschlich annotierten Demonstrationen und ermöglicht es den Modellen, fortschrittliche Denkstrukturen wie Selbstreflexion und dynamische Strategieanpassung zu entwickeln.
WARUM - Er ist relevant, weil er die Grenzen traditioneller, auf menschlichen Demonstrationen basierender Techniken überwindet und überlegene Leistungen in überprüfbaren Aufgaben wie Mathematik, Programmierung und STEM bietet. Dies kann zu autonomeren und leistungsfähigeren Modellen führen.
WER - Die Hauptakteure umfassen die Forscher, die DeepSeek-R1 entwickelt haben, und die wissenschaftliche Gemeinschaft, die fortschrittliche KI-Modelle studiert und implementiert. Die GitHub-Community ist aktiv an der Diskussion und Verbesserung des Modells beteiligt.
WO - Es positioniert sich im Markt für fortschrittliche KI, speziell im Bereich der Large Language Models und des Reinforcement Learning. Es ist Teil des Forschungs- und Entwicklungsökosystems für KI-Modelle.
WANN - Der Artikel wurde im Februar 2025 veröffentlicht, was darauf hinweist, dass DeepSeek-R1 ein relativ neues, aber bereits in der akademischen Forschung etabliertes Modell ist.
GESCHÄFTLICHE AUSWIRKUNGEN:
- Chancen: Integration von DeepSeek-R1 zur Verbesserung der Denkfähigkeiten bestehender Modelle, um autonomere und leistungsfähigere Lösungen zu bieten.
- Risiken: Wettbewerb mit Modellen, die fortschrittliche RL-Techniken nutzen, potenzielle Notwendigkeit von Investitionen in Forschung und Entwicklung, um wettbewerbsfähig zu bleiben.
- Integration: Mögliche Integration in den bestehenden Stack, um die Denkfähigkeiten der Unternehmens-KI-Modelle zu verbessern.
TECHNISCHE ZUSAMMENFASSUNG:
- Kern-Technologie-Stack: Python, Go, Machine Learning-Frameworks, neuronale Netze, RL-Algorithmen.
- Skalierbarkeit: Das Modell kann skaliert werden, um die Denkfähigkeiten zu verbessern, erfordert jedoch erhebliche Rechenressourcen.
- Technische Differenzierer: Nutzung von Group Relative Policy Optimization (GRPO) und Umgehung der Phase des überwachten Feinabstimmens, was eine freiere und autonomere Exploration des Modells ermöglicht.
Anwendungsfälle #
- Private AI Stack: Integration in proprietäre Pipelines
- Client-Lösungen: Implementierung für Kundenprojekte
- Beschleunigung der Entwicklung: Reduzierung der Time-to-Market für Projekte
Feedback von Dritten #
Community-Feedback: Die Nutzer schätzen DeepSeek-R1 für seine Denkfähigkeiten, äußern jedoch Bedenken hinsichtlich Problemen wie Wiederholungen und Lesbarkeit. Einige schlagen die Verwendung quantisierter Versionen vor, um die Effizienz zu verbessern, und schlagen vor, Cold-Start-Daten zu integrieren, um die Leistung zu verbessern.
Ressourcen #
Original-Links #
Artikel empfohlen und ausgewählt vom Human Technology eXcellence Team, erstellt mit KI (in diesem Fall mit LLM HTX-EU-Mistral3.1Small) am 2025-09-18 15:08 Quelle: https://www.nature.com/articles/s41586-025-09422-z
Die HTX-Perspektive #
Dieses Thema steht im Mittelpunkt dessen, was wir bei HTX entwickeln. Die hier diskutierte Technologie — ob KI-Agenten, Sprachmodelle oder Dokumentenverarbeitung — repräsentiert genau die Art von Fähigkeiten, die europäische Unternehmen benötigen, aber zu ihren eigenen Bedingungen eingesetzt.
Die Herausforderung ist nicht, ob diese Technologie funktioniert. Das tut sie. Die Herausforderung ist, sie einzusetzen, ohne Unternehmensdaten an US-Server zu senden, ohne die DSGVO zu verletzen und ohne Lieferantenabhängigkeiten zu schaffen.
Deshalb haben wir ORCA entwickelt — einen privaten Unternehmens-Chatbot, der diese Fähigkeiten auf Ihre Infrastruktur bringt. Gleiche Leistung wie ChatGPT, aber Ihre Daten verlassen nie Ihren Perimeter.
Möchten Sie wissen, ob Ihr Unternehmen bereit für KI ist? Machen Sie unser kostenloses Assessment — 5 Minuten, personalisierter Bericht, umsetzbare Roadmap.
Verwandte Artikel #
- [2505.03335] Absolute Nullpunkt: Verstärktes Selbstspiel-Räsonieren mit Null Daten - Tech
- [2505.03335v2] Absolute Nullpunkt: Verstärktes Selbstspiel-Rückschluss mit Null Daten - Tech
- [2505.24863] AlphaOne: Denkmodelle, die beim Testen langsam und schnell denken - Foundation Model
FAQ
Können große Sprachmodelle auf privater Infrastruktur laufen?
Ja. Open-Source-Modelle wie LLaMA, Mistral, DeepSeek und Qwen können On-Premise oder auf europäischer Cloud laufen. Diese Modelle erreichen eine mit GPT-4 vergleichbare Leistung für die meisten Geschäftsaufgaben, mit dem Vorteil vollständiger Datensouveränität.
Welches LLM ist am besten für den geschäftlichen Einsatz?
Das beste Modell hängt von Ihrem Anwendungsfall ab. Für Dokumentenanalyse und Chat zeichnen sich Mistral und LLaMA aus. Für Datenanalyse bietet DeepSeek starkes Reasoning. HTX's Ansatz ist modell-agnostisch: ORCA unterstützt mehrere Modelle.