Tipo: Discusión de Hacker News Enlace original: https://news.ycombinator.com/item?id=45571423 Fecha de publicación: 2025-10-13
Autor: frenchmajesty
Resumen #
QUÉ - Técnicas para obtener clasificaciones coherentes de modelos lingüísticos grandes (LLM) estocásticos, con implementación en Golang. Resuelve el problema de la inconsistencia en las etiquetas generadas por los modelos.
POR QUÉ - Relevante para mejorar la fiabilidad de las clasificaciones automatizadas, reduciendo errores y costos asociados a la etiquetación manual. Resuelve el problema de la inconsistencia en las etiquetas generadas por los modelos.
QUIÉN - Autor: Verdi Oct. Comunidad de desarrolladores e ingenieros de ML, usuarios de API de modelos lingüísticos.
DÓNDE - Posicionado en el mercado de soluciones de IA para la etiquetación automatizada, dirigido a equipos de desarrollo y empresas que utilizan LLMs.
CUÁNDO - Nuevo enfoque, tendencia emergente. La discusión en Hacker News indica interés actual y posible adopción.
IMPACTO EN EL NEGOCIO:
- Oportunidades: Mejora en la calidad de las etiquetas de datos, reducción de costos operativos, aumento de la eficiencia en los procesos de etiquetado.
- Riesgos: Dependencia de API externas, posible obsolescencia tecnológica.
- Integración: Posible integración con el stack existente para la etiquetación automatizada, mejora de los flujos de trabajo de etiquetado de datos.
RESUMEN TÉCNICO:
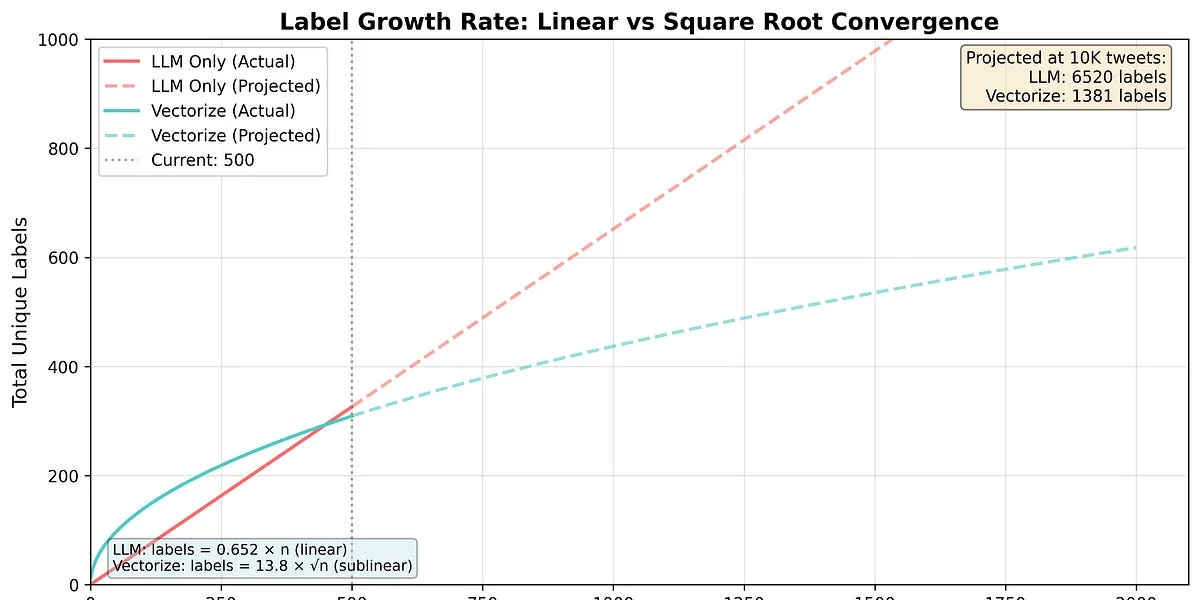
- Pila tecnológica principal: Golang, API de modelos lingüísticos (por ejemplo, OpenAI), logit_bias, json_schema.
- Escalabilidad: Buena escalabilidad gracias al uso de API externas, limitaciones relacionadas con la gestión de grandes volúmenes de datos.
- Diferenciadores técnicos: Uso de logit_bias y json_schema para mejorar la coherencia de las etiquetas, implementación en Golang para un rendimiento elevado.
DISCUSIÓN DE HACKER NEWS: La discusión en Hacker News ha destacado principalmente los problemas relacionados con el rendimiento y la resolución de problemas técnicos. Los usuarios han discutido los desafíos relacionados con la implementación de soluciones de etiquetado automatizado y las posibles soluciones técnicas. El sentimiento general es de interés y curiosidad, con cierta cautela respecto a la dependencia de API externas. Los temas principales que han surgido han sido el rendimiento, el problema técnico y la gestión de bases de datos. La comunidad ha mostrado un interés práctico y técnico, con un enfoque en la resolución de problemas concretos relacionados con el uso de LLMs.
Casos de uso #
- Private AI Stack: Integración en pipelines propietarias
- Client Solutions: Implementación para proyectos de clientes
Feedback de terceros #
Feedback de la comunidad: La comunidad de HackerNews ha comentado con enfoque en el rendimiento, el problema (20 comentarios).
Recursos #
Enlaces Originales #
- My trick for getting consistent classification from LLMs - Enlace original
Artículo recomendado y seleccionado por el equipo Human Technology eXcellence elaborado mediante inteligencia artificial (en este caso con LLM HTX-EU-Mistral3.1Small) el 2025-10-23 13:56 Fuente original: https://news.ycombinator.com/item?id=45571423
La Perspectiva HTX #
Este tema está en el corazón de lo que construimos en HTX. La tecnología discutida aquí — ya sean agentes IA, modelos de lenguaje o procesamiento de documentos — representa exactamente el tipo de capacidades que las empresas europeas necesitan, pero desplegadas en sus propios términos.
El desafío no es si esta tecnología funciona. Funciona. El desafío es desplegarla sin enviar datos empresariales a servidores estadounidenses, sin violar el RGPD y sin crear dependencias de proveedores de las que no puedas salir.
Por eso construimos ORCA — un chatbot empresarial privado que lleva estas capacidades a tu infraestructura. Misma potencia que ChatGPT, pero tus datos nunca salen de tu perímetro.
¿Quieres saber si tu empresa está lista para la IA? Haz nuestra evaluación gratuita — 5 minutos, informe personalizado, hoja de ruta accionable.
Artículos Relacionados #
- Muestra HN: AutoThink – Mejora el rendimiento de LLM local con razonamiento adaptativo - LLM, Foundation Model
- Muestra HN: Fallinorg - Aplicación de Mac offline que organiza archivos por significado - AI
- Muestra HN: Whispering – Dictado de código abierto, primero local, en el que puedes confiar - Rust
FAQ
¿Pueden los grandes modelos de lenguaje funcionar en infraestructura privada?
Sí. Modelos de código abierto como LLaMA, Mistral, DeepSeek y Qwen pueden ejecutarse on-premise o en nube europea. Estos modelos alcanzan un rendimiento comparable a GPT-4 para la mayoría de tareas empresariales, con la ventaja de la soberanía total sobre los datos.
¿Cuál es el mejor LLM para uso empresarial?
El mejor modelo depende de tu caso de uso. Para análisis de documentos y chat, Mistral y LLaMA destacan. Para análisis de datos, DeepSeek ofrece razonamiento sólido. El enfoque de HTX es agnóstico: ORCA soporta múltiples modelos.