Tipo: Repositorio GitHub Enlace original: https://github.com/neuml/paperetl Fecha de publicación: 2025-09-04
Resumen #
QUÉ #
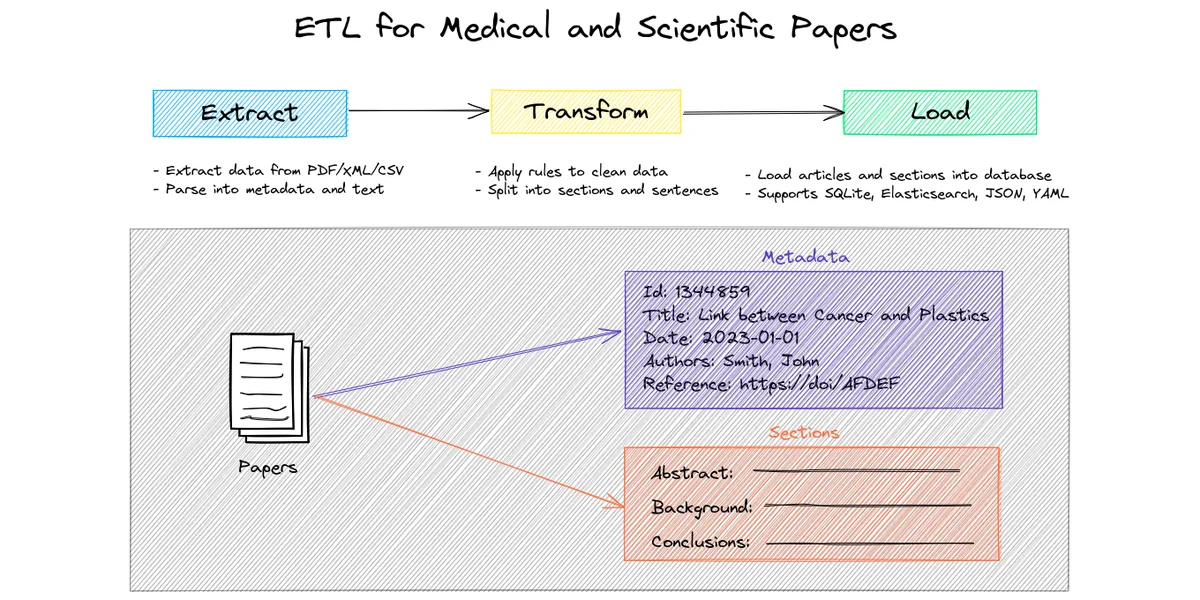
PaperETL es una librería ETL (Extract, Transform, Load) para el procesamiento de artículos médicos y científicos. Soporta varios formatos de entrada (PDF, XML, CSV) y diferentes almacenes de datos (SQLite, JSON, YAML, Elasticsearch).
POR QUÉ #
PaperETL es relevante para el negocio de IA porque automatiza la extracción y transformación de datos científicos, facilitando el análisis e integración de información crítica para la investigación y desarrollo. Resuelve el problema de la gestión y estandarización de datos heterogéneos provenientes de diversas fuentes académicas.
QUIÉN #
Los actores principales son la comunidad de código abierto y los desarrolladores que contribuyen al proyecto en GitHub. No hay competidores directos, pero existen otras soluciones ETL genéricas que podrían ser adaptadas para propósitos similares.
DÓNDE #
PaperETL se posiciona en el mercado de soluciones ETL especializadas para la gestión de datos científicos y médicos. Es parte del ecosistema de IA que apoya la investigación y el análisis de datos académicos.
CUÁNDO #
PaperETL es un proyecto relativamente nuevo pero en rápida evolución. Su madurez está en fase de crecimiento, con actualizaciones frecuentes y una comunidad activa.
IMPACTO EN EL NEGOCIO #
- Oportunidades: Integración con nuestro stack para automatizar la extracción y transformación de datos científicos, mejorando la calidad y velocidad de los análisis.
- Riesgos: Dependencia de una instancia local de GROBID para el análisis de PDF, lo que podría representar un cuello de botella.
- Integración: Posible integración con sistemas de gestión de datos existentes para enriquecer el conjunto de datos de investigación y desarrollo.
RESUMEN TÉCNICO #
- Tecnología principal: Python, SQLite, JSON, YAML, Elasticsearch, GROBID.
- Escalabilidad: Buena escalabilidad para pequeños y medianos conjuntos de datos, pero podría requerir optimizaciones para grandes volúmenes de datos.
- Diferenciadores técnicos: Soporte para varios formatos de entrada y almacenes de datos, integración con Elasticsearch para la búsqueda de texto completo.
Casos de uso #
- Private AI Stack: Integración en pipelines propietarias
- Soluciones para clientes: Implementación para proyectos de clientes
- Aceleración del desarrollo: Reducción del tiempo de comercialización de proyectos
- Inteligencia estratégica: Entrada para la hoja de ruta tecnológica
- Análisis competitivo: Monitoreo del ecosistema de IA
Recursos #
Enlaces Originales #
- paperetl - Enlace original
Artículo recomendado y seleccionado por el equipo Human Technology eXcellence elaborado mediante inteligencia artificial (en este caso con LLM HTX-EU-Mistral3.1Small) el 2025-09-04 19:15 Fuente original: https://github.com/neuml/paperetl
La Perspectiva HTX #
Este tema está en el corazón de lo que construimos en HTX. La tecnología discutida aquí — ya sean agentes IA, modelos de lenguaje o procesamiento de documentos — representa exactamente el tipo de capacidades que las empresas europeas necesitan, pero desplegadas en sus propios términos.
El desafío no es si esta tecnología funciona. Funciona. El desafío es desplegarla sin enviar datos empresariales a servidores estadounidenses, sin violar el RGPD y sin crear dependencias de proveedores de las que no puedas salir.
Por eso construimos ORCA — un chatbot empresarial privado que lleva estas capacidades a tu infraestructura. Misma potencia que ChatGPT, pero tus datos nunca salen de tu perímetro.
¿Quieres saber si tu empresa está lista para la IA? Haz nuestra evaluación gratuita — 5 minutos, informe personalizado, hoja de ruta accionable.
Artículos Relacionados #
- Elysia: Marco de Agencia Impulsado por Árboles de Decisión - Best Practices, Python, AI Agent
- LangExtract se traduce como “Extracción de Lenguaje”. - Python, LLM, Open Source
- SurfSense se traduce como “Sentido de Surf” o “Detección de Surf” en español. - Open Source, Python
FAQ
¿Se pueden usar herramientas IA de código abierto de forma segura en la empresa?
Absolutamente. Modelos de código abierto como LLaMA, Mistral y DeepSeek están listos para producción y son usados por grandes empresas. La clave es el despliegue correcto: ejecutarlos en tu propia infraestructura garantiza la privacidad de datos y el cumplimiento del RGPD.
¿Cuál es la ventaja de la IA de código abierto frente a las soluciones propietarias?
La IA de código abierto ofrece tres ventajas clave: sin dependencia de proveedor, total transparencia sobre cómo funciona el modelo, y la capacidad de funcionar completamente en tu infraestructura.