Tipo: Hacker News Discussion
Link originale: https://news.ycombinator.com/item?id=45571423
Data pubblicazione: 2025-10-13
Autore: frenchmajesty
Sintesi #
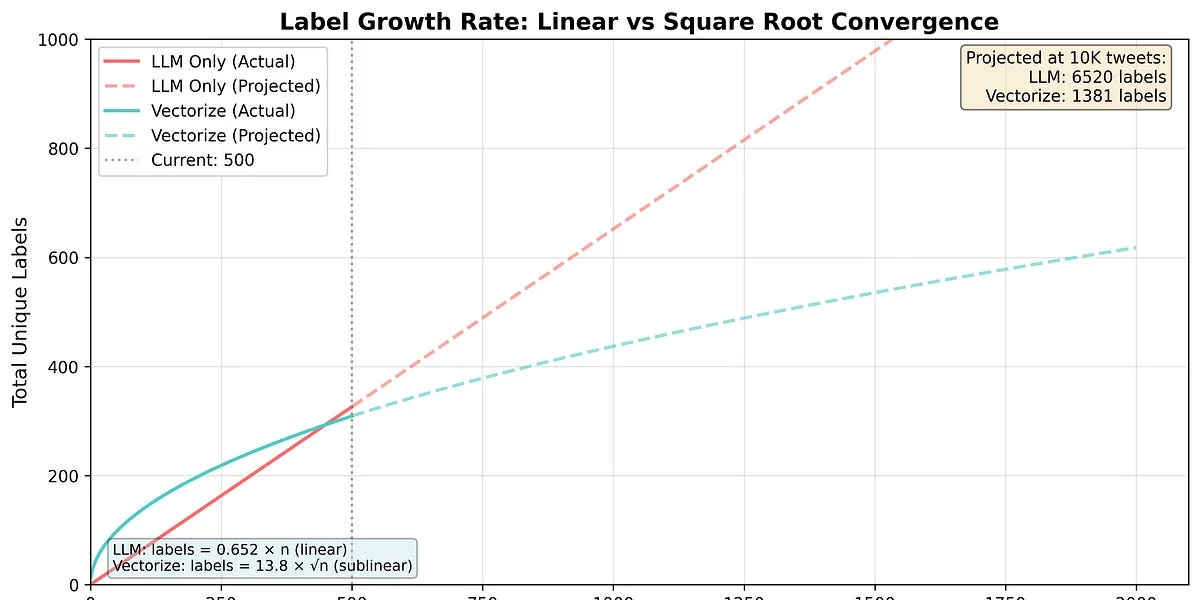
WHAT - Tecniche per ottenere classificazioni coerenti da modelli linguistici grandi (LLM) stocastici, con implementazione in Golang. Risolve il problema dell’inconsistenza nelle etichette generate dai modelli.
WHY - Rilevante per migliorare l’affidabilità delle classificazioni automatizzate, riducendo errori e costi associati all’etichettatura manuale. Risolve il problema dell’inconsistenza nelle etichette generate dai modelli.
WHO - Autore: Verdi Oct. Community di sviluppatori e ingegneri ML, utenti di API di modelli linguistici.
WHERE - Posizionato nel mercato delle soluzioni AI per l’etichettatura automatizzata, rivolto a team di sviluppo e aziende che utilizzano LLMs.
WHEN - Nuovo approccio, trend emergente. La discussione su Hacker News indica interesse attuale e potenziale adozione.
BUSINESS IMPACT:
- Opportunità: Miglioramento della qualità delle etichette dati, riduzione dei costi operativi, aumento dell’efficienza nei processi di etichettatura.
- Rischi: Dipendenza da API esterne, potenziale obsolescenza tecnologica.
- Integrazione: Possibile integrazione con stack esistente per l’etichettatura automatizzata, miglioramento dei flussi di lavoro di data labeling.
TECHNICAL SUMMARY:
- Core technology stack: Golang, API di modelli linguistici (es. OpenAI), logit_bias, json_schema.
- Scalabilità: Buona scalabilità grazie all’uso di API esterne, limiti legati alla gestione di grandi volumi di dati.
- Differenziatori tecnici: Uso di logit_bias e json_schema per migliorare la coerenza delle etichette, implementazione in Golang per performance elevate.
DISCUSSIONE HACKER NEWS: La discussione su Hacker News ha evidenziato principalmente le problematiche legate alle performance e alla risoluzione dei problemi tecnici. Gli utenti hanno discusso le sfide legate all’implementazione di soluzioni di etichettatura automatizzata e le potenziali soluzioni tecniche. Il sentimento generale è di interesse e curiosità, con una certa cautela riguardo alla dipendenza da API esterne. I temi principali emersi sono stati la performance, il problema tecnico, e la gestione dei database. La community ha mostrato un interesse pratico e tecnico, con un focus sulla risoluzione dei problemi concreti legati all’uso di LLMs.
Casi d’uso #
- Private AI Stack: Integrazione in pipeline proprietarie
- Client Solutions: Implementazione per progetti clienti
Feedback da terzi #
Community feedback: La community HackerNews ha commentato con focus su performance, problem (20 commenti).
Risorse #
Link Originali #
- My trick for getting consistent classification from LLMs - Link originale
Articolo segnalato e selezionato dal team Human Technology eXcellence elaborato tramite intelligenza artificiale (in questo caso con LLM HTX-EU-Mistral3.1Small) il 2025-10-23 13:56 Fonte originale: https://news.ycombinator.com/item?id=45571423
Il Punto di Vista HTX #
Questo tema è al centro di ciò che costruiamo in HTX. La tecnologia discussa qui — che si tratti di agenti AI, modelli linguistici o elaborazione documenti — rappresenta esattamente il tipo di capacità di cui le aziende europee hanno bisogno, ma implementata alle proprie condizioni.
La sfida non è se questa tecnologia funziona. Funziona. La sfida è implementarla senza inviare i dati aziendali a server USA, senza violare il GDPR e senza creare dipendenze da fornitori da cui non puoi uscire.
Per questo abbiamo costruito ORCA — un chatbot aziendale privato che porta queste capacità sulla tua infrastruttura. Stessa potenza di ChatGPT, ma i tuoi dati non escono mai dal tuo perimetro. Nessun costo per utente, nessuna fuga di dati, nessun problema di compliance.
Vuoi sapere quanto è pronta la tua azienda per l’AI? Fai il nostro Assessment gratuito della AI Readiness — 5 minuti, report personalizzato, roadmap operativa.
Articoli Correlati #
- Ask HN: What is the best LLM for consumer grade hardware? - LLM, Foundation Model
- Ask HN: What is the best way to provide continuous context to models? - AI, Foundation Model, Natural Language Processing
- Litestar is worth a look - Best Practices, Python
FAQ
I modelli linguistici di grandi dimensioni possono girare su infrastruttura privata?
Sì. Modelli open source come LLaMA, Mistral, DeepSeek e Qwen possono funzionare on-premise o su cloud europeo. Questi modelli raggiungono prestazioni paragonabili a GPT-4 per la maggior parte dei task aziendali, con il vantaggio della completa sovranità sui dati. Lo stack PRISMA di HTX è progettato per implementare questi modelli per le PMI europee.
Quale LLM è migliore per uso aziendale?
Il modello migliore dipende dal caso d'uso. Per analisi documenti e chat, modelli come Mistral e LLaMA eccellono. Per analisi dati, DeepSeek offre forte ragionamento. L'approccio di HTX è model-agnostic: ORCA supporta più modelli così puoi scegliere il più adatto senza vendor lock-in.