Tipo: GitHub Repository
Link originale: https://github.com/neuml/paperetl
Data pubblicazione: 2025-09-04
Sintesi #
WHAT #
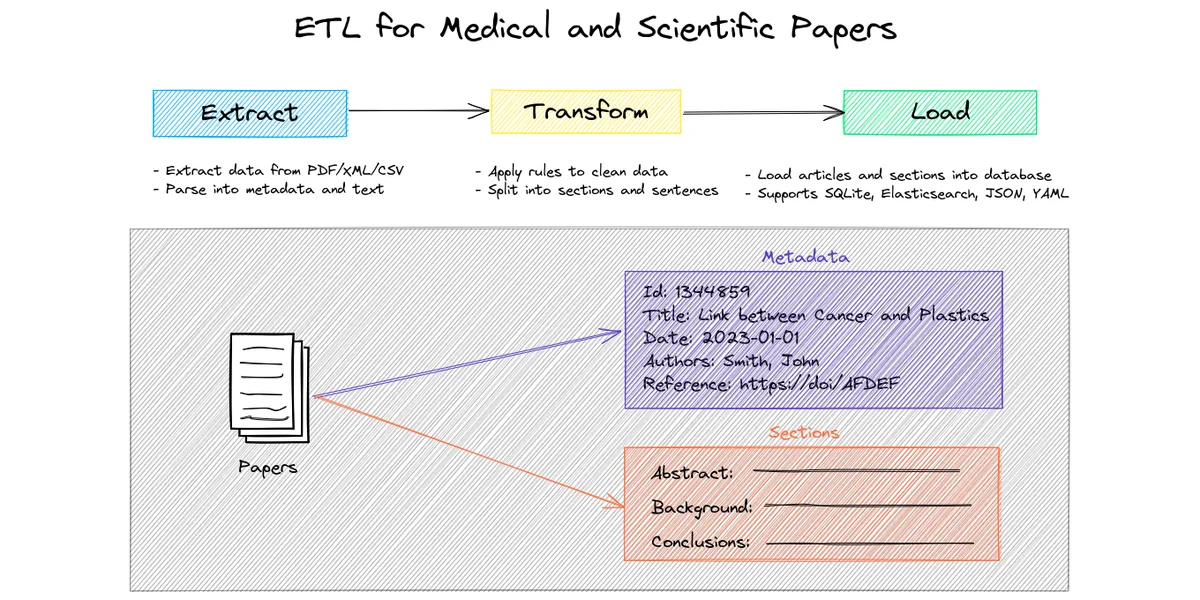
PaperETL è una libreria ETL (Extract, Transform, Load) per l’elaborazione di articoli medici e scientifici. Supporta vari formati di input (PDF, XML, CSV) e diversi datastore (SQLite, JSON, YAML, Elasticsearch).
WHY #
PaperETL è rilevante per il business AI perché automatizza l’estrazione e la trasformazione di dati scientifici, facilitando l’analisi e l’integrazione di informazioni critiche per la ricerca e lo sviluppo. Risolve il problema della gestione e standardizzazione di dati eterogenei provenienti da diverse fonti accademiche.
WHO #
Gli attori principali sono la community open-source e gli sviluppatori che contribuiscono al progetto su GitHub. Non ci sono competitor diretti, ma esistono altre soluzioni ETL generiche che potrebbero essere adattate per scopi simili.
WHERE #
PaperETL si posiziona nel mercato delle soluzioni ETL specializzate per la gestione di dati scientifici e medici. È parte dell’ecosistema AI che supporta la ricerca e l’analisi di dati accademici.
WHEN #
PaperETL è un progetto relativamente nuovo ma in rapida evoluzione. La sua maturità è in fase di crescita, con aggiornamenti frequenti e una community attiva.
BUSINESS IMPACT #
- Opportunità: Integrazione con il nostro stack per automatizzare l’estrazione e la trasformazione di dati scientifici, migliorando la qualità e la velocità delle analisi.
- Rischi: Dipendenza da un’istanza locale di GROBID per il parsing dei PDF, che potrebbe rappresentare un collo di bottiglia.
- Integrazione: Possibile integrazione con sistemi di gestione dei dati esistenti per arricchire il dataset di ricerca e sviluppo.
TECHNICAL SUMMARY #
- Core technology stack: Python, SQLite, JSON, YAML, Elasticsearch, GROBID.
- Scalabilità: Buona scalabilità per piccoli e medi dataset, ma potrebbe richiedere ottimizzazioni per grandi volumi di dati.
- Differenziatori tecnici: Supporto per vari formati di input e datastore, integrazione con Elasticsearch per la ricerca full-text.
Casi d’uso #
- Private AI Stack: Integrazione in pipeline proprietarie
- Client Solutions: Implementazione per progetti clienti
- Development Acceleration: Riduzione time-to-market progetti
- Strategic Intelligence: Input per roadmap tecnologica
- Competitive Analysis: Monitoring ecosystem AI
Risorse #
Link Originali #
- paperetl - Link originale
Articolo segnalato e selezionato dal team Human Technology eXcellence elaborato tramite intelligenza artificiale (in questo caso con LLM HTX-EU-Mistral3.1Small) il 2025-09-04 19:15 Fonte originale: https://github.com/neuml/paperetl
Il Punto di Vista HTX #
Questo tema è al centro di ciò che costruiamo in HTX. La tecnologia discussa qui — che si tratti di agenti AI, modelli linguistici o elaborazione documenti — rappresenta esattamente il tipo di capacità di cui le aziende europee hanno bisogno, ma implementata alle proprie condizioni.
La sfida non è se questa tecnologia funziona. Funziona. La sfida è implementarla senza inviare i dati aziendali a server USA, senza violare il GDPR e senza creare dipendenze da fornitori da cui non puoi uscire.
Per questo abbiamo costruito ORCA — un chatbot aziendale privato che porta queste capacità sulla tua infrastruttura. Stessa potenza di ChatGPT, ma i tuoi dati non escono mai dal tuo perimetro. Nessun costo per utente, nessuna fuga di dati, nessun problema di compliance.
Vuoi sapere quanto è pronta la tua azienda per l’AI? Fai il nostro Assessment gratuito della AI Readiness — 5 minuti, report personalizzato, roadmap operativa.
Articoli Correlati #
- Automatically annotate papers using LLMs - LLM, Open Source
- Elysia: Agentic Framework Powered by Decision Trees - Best Practices, Python, AI Agent
- The LLM Red Teaming Framework - Open Source, Python, LLM
FAQ
Gli strumenti AI open source possono essere usati in modo sicuro in azienda?
Assolutamente sì. Modelli open source come LLaMA, Mistral e DeepSeek sono pronti per la produzione e usati da grandi aziende. La chiave è l'implementazione corretta: farli girare sulla propria infrastruttura garantisce privacy dei dati e conformità GDPR. Lo stack PRISMA di HTX è costruito per implementare modelli open source per le aziende europee.
Qual è il vantaggio dell'AI open source rispetto alle soluzioni proprietarie?
L'AI open source offre tre vantaggi chiave: nessun vendor lock-in, piena trasparenza su come funziona il modello, e la possibilità di girare interamente sulla tua infrastruttura. Questo significa costi a lungo termine inferiori, migliore privacy e controllo completo sul tuo stack AI.