Tipo: Artículo web Enlace original: https://www.nature.com/articles/s41586-025-09422-z Fecha de publicación: 2025-02-14
Resumen #
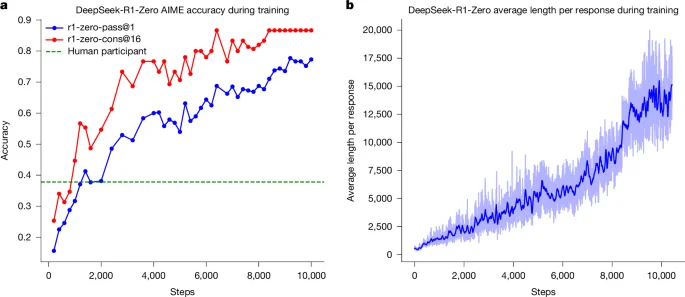
QUÉ - El artículo de Nature describe DeepSeek-R1, un modelo de IA que utiliza el aprendizaje por refuerzo (RL) para mejorar las capacidades de razonamiento de los Large Language Models (LLMs). Este enfoque elimina la necesidad de demostraciones anotadas por humanos, permitiendo que los modelos desarrollen patrones de razonamiento avanzados como la auto-reflexión y la adaptación dinámica de estrategias.
POR QUÉ - Es relevante porque supera los límites de las técnicas tradicionales basadas en demostraciones humanas, ofreciendo un rendimiento superior en tareas verificables como matemáticas, programación y STEM. Esto puede llevar a modelos más autónomos y eficientes.
QUIÉN - Los actores principales incluyen a los investigadores que desarrollaron DeepSeek-R1 y la comunidad científica que estudia e implementa modelos de IA avanzados. La comunidad de GitHub está activa en discutir y mejorar el modelo.
DÓNDE - Se posiciona en el mercado de las IA avanzadas, específicamente en el sector de los Large Language Models y el aprendizaje por refuerzo. Es parte del ecosistema de investigación y desarrollo de modelos de inteligencia artificial.
CUÁNDO - El artículo fue publicado en febrero de 2025, lo que indica que DeepSeek-R1 es un modelo relativamente nuevo pero ya consolidado en la investigación académica.
IMPACTO EN LOS NEGOCIOS:
- Oportunidades: Integración de DeepSeek-R1 para mejorar las capacidades de razonamiento de los modelos existentes, ofreciendo soluciones más autónomas y eficientes.
- Riesgos: Competencia con modelos que utilizan técnicas de RL avanzadas, posible necesidad de inversiones en investigación y desarrollo para mantener la competitividad.
- Integración: Posible integración con el stack existente para mejorar las capacidades de razonamiento de los modelos de IA empresariales.
RESUMEN TÉCNICO:
- Pila tecnológica principal: Python, Go, frameworks de machine learning, redes neuronales, algoritmos de RL.
- Escalabilidad: El modelo puede escalarse para mejorar las capacidades de razonamiento, pero requiere recursos computacionales significativos.
- Diferenciadores técnicos: Uso de Group Relative Policy Optimization (GRPO) y omisión de la fase de fine-tuning supervisado, permitiendo una exploración más libre y autónoma del modelo.
Casos de uso #
- Private AI Stack: Integración en pipelines propietarias
- Client Solutions: Implementación para proyectos de clientes
- Development Acceleration: Reducción del time-to-market de proyectos
Feedback de terceros #
Feedback de la comunidad: Los usuarios valoran DeepSeek-R1 por su capacidad de razonamiento, pero expresan preocupaciones sobre problemas como la repetición y la legibilidad. Algunos sugieren utilizar versiones cuantizadas para mejorar la eficiencia y proponen integrar datos de cold-start para mejorar el rendimiento.
Recursos #
Enlaces Originales #
- DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning | Nature - Enlace original
Artículo recomendado y seleccionado por el equipo Human Technology eXcellence elaborado mediante inteligencia artificial (en este caso con LLM HTX-EU-Mistral3.1Small) el 2025-09-18 15:08 Fuente original: https://www.nature.com/articles/s41586-025-09422-z