Tipo: Artículo web Enlace original: https://verdik.substack.com/p/how-to-get-consistent-classification Fecha de publicación: 2025-10-23
Autor: Verdi
Resumen #
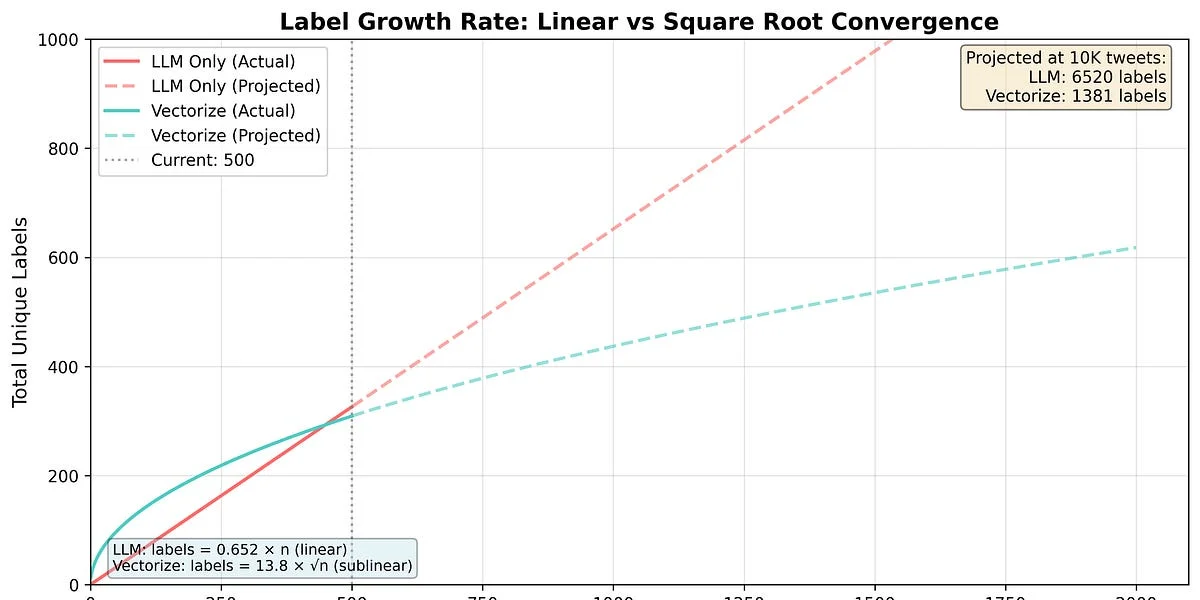
QUÉ - Este artículo describe una técnica para obtener clasificaciones coherentes de modelos lingüísticos de grandes dimensiones (LLM) que son intrínsecamente estocásticos. El autor presenta un método para determinar etiquetas consistentes utilizando embeddings vectoriales y búsqueda vectorial, con una implementación benchmarked en Golang.
POR QUÉ - Es relevante para el negocio de la IA porque aborda el problema de la variabilidad de las etiquetas generadas por los LLM, mejorando la coherencia y la eficiencia en la clasificación de grandes volúmenes de datos no etiquetados.
QUIÉN - El autor es Verdi, un experto en machine learning. Los actores principales incluyen desarrolladores de ML, empresas que utilizan LLM para el etiquetado de datos, y la comunidad de investigación en IA.
DÓNDE - Se posiciona en el mercado de soluciones de IA para el etiquetado de datos, ofreciendo un método alternativo a las API de los grandes proveedores de modelos.
CUÁNDO - La técnica es actual y responde a una necesidad emergente en el contexto del uso generalizado de LLM para el etiquetado de datos. La madurez de la solución se demuestra a través de benchmarks y implementaciones prácticas.
IMPACTO EN EL NEGOCIO:
- Oportunidades: Implementar esta técnica puede reducir costos y mejorar la coherencia en el etiquetado de datos, haciendo más eficiente el proceso de entrenamiento de modelos de machine learning.
- Riesgos: La dependencia de API de terceros para el etiquetado podría mitigarse, pero es necesario invertir en infraestructura para la gestión de embeddings vectoriales.
- Integración: La técnica puede integrarse en el stack existente utilizando Pinecone para la búsqueda vectorial y embeddings generados por modelos como GPT-3.5.
RESUMEN TÉCNICO:
- Pila tecnológica principal: Golang para la implementación, GPT-3.5 para la generación de etiquetas, voyage-.-lite para el embedding (dimensión 768), Pinecone para la búsqueda vectorial.
- Escalabilidad y límites arquitectónicos: La solución es escalable pero requiere recursos computacionales para la gestión de embeddings vectoriales y búsqueda vectorial. Los principales límites están relacionados con la latencia inicial y los costos de configuración.
- Diferenciadores técnicos clave: Uso de embeddings vectoriales para agrupar etiquetas inconsistentes, búsqueda vectorial para encontrar etiquetas similares, y compresión de rutas para garantizar coherencia en las etiquetas.
Casos de uso #
- Private AI Stack: Integración en pipelines propietarias
- Client Solutions: Implementación para proyectos de clientes
- Strategic Intelligence: Input para la hoja de ruta tecnológica
- Competitive Analysis: Monitoreo del ecosistema de IA
Recursos #
Enlaces Originales #
- How to Get Consistent Classification From Inconsistent LLMs? - Enlace original
Artículo recomendado y seleccionado por el equipo Human Technology eXcellence elaborado mediante inteligencia artificial (en este caso con LLM HTX-EU-Mistral3.1Small) el 2025-10-23 13:57 Fuente original: https://verdik.substack.com/p/how-to-get-consistent-classification
Artículos Relacionados #
- [2505.03335] Cero Absoluto: Razonamiento de Autojuego Reforzado con Cero Datos - Tech
- DeepSeek-R1 incentiva el razonamiento en los modelos de lenguaje mediante el aprendizaje por refuerzo | Nature - LLM, AI, Best Practices
- [2505.24864] ProRL: El Aprendizaje por Refuerzo Prolongado Expande los Límites del Razonamiento en Modelos de Lenguaje Grandes - LLM, Foundation Model