Tipo: Discusión de Hacker News Enlace original: https://news.ycombinator.com/item?id=45114245 Fecha de publicación: 2025-09-03
Autor: lastdong
Resumen #
VibeVoice: Un Modelo de Text-to-Speech Open-Source de Vanguardia #
QUÉ - VibeVoice es un framework open-source para generar audio conversacional expresivo y de larga duración, como podcasts, a partir de texto. Resuelve problemas de escalabilidad, coherencia del hablante y naturalidad en las conversaciones.
POR QUÉ - Es relevante para el negocio de la IA porque ofrece una solución avanzada para la síntesis de voz, mejorando la interacción humano-máquina y la producción de contenidos de audio de alta calidad.
QUIÉNES - Los actores principales incluyen a Microsoft, que desarrolló el framework, y la comunidad open-source que contribuye a su desarrollo y mejora.
DÓNDE - Se posiciona en el mercado de soluciones TTS, ofreciendo una alternativa avanzada respecto a los modelos tradicionales, e integra el ecosistema de IA para aplicaciones de síntesis de voz.
CUÁNDO - Es un proyecto relativamente nuevo pero ya consolidado, con un potencial de crecimiento significativo en el sector de la síntesis de voz.
IMPACTO EN EL NEGOCIO:
- Oportunidades: Integración con plataformas de contenido de audio para crear podcasts y otras formas de medios vocales. Posibilidad de asociaciones con empresas de medios y entretenimiento.
- Riesgos: Competencia con otros modelos TTS avanzados y la necesidad de mantener una ventaja tecnológica.
- Integración: Puede ser integrado en el stack existente para mejorar las capacidades de síntesis de voz e interacción con los usuarios.
RESUMEN TÉCNICO:
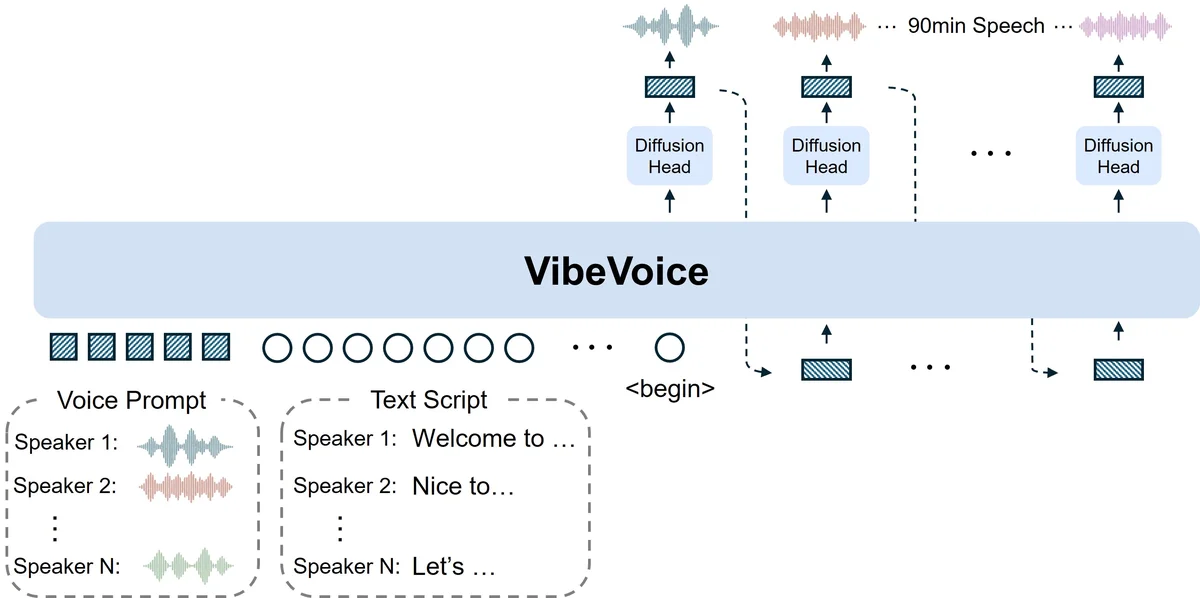
- Pila tecnológica principal: Utiliza tokenizadores de discurso continuo (Acústico y Semántico) de bajo frame rate, un framework de difusión next-token y un Large Language Model (LLM) para la comprensión del contexto.
- Escalabilidad: Eficiente en la gestión de secuencias largas y multi-hablante, con una escalabilidad superior a los modelos tradicionales.
- Diferenciadores técnicos: Alta fidelidad de audio, coherencia del hablante y naturalidad en las conversaciones.
DISCUSIÓN DE HACKER NEWS: La discusión en Hacker News ha destacado principalmente la solución ofrecida por VibeVoice, con un enfoque en su capacidad para resolver problemas específicos en el campo de la síntesis de voz. Los temas principales que han surgido se refieren a la efectividad de la solución propuesta y su potencial impacto en el mercado. El sentimiento general de la comunidad es positivo, reconociendo el valor innovador del framework.
Casos de uso #
- Private AI Stack: Integración en pipelines propietarias
- Soluciones para clientes: Implementación para proyectos de clientes
- Aceleración del desarrollo: Reducción del time-to-market de proyectos
- Inteligencia estratégica: Entradas para la hoja de ruta tecnológica
- Análisis competitivo: Monitoreo del ecosistema de IA
Feedback de terceros #
Feedback de la comunidad: La comunidad de HackerNews ha comentado con enfoque en la solución (20 comentarios).
Recursos #
Enlaces Originales #
- VibeVoice: Un Modelo de Text-to-Speech Open-Source de Vanguardia - Enlace original
Artículo señalado y seleccionado por el equipo Human Technology eXcellence elaborado mediante inteligencia artificial (en este caso con LLM HTX-EU-Mistral3.1Small) el 2025-09-04 18:55 Fuente original: https://news.ycombinator.com/item?id=45114245
Artículos Relacionados #
- Muestra HN: Whispering – Dictado de código abierto, primero local, en el que puedes confiar - Rust
- SymbolicAI: Una perspectiva neuro-simbólica sobre los LLMs - Foundation Model, Python, Best Practices
- Nanonets-OCR-s – Modelo de OCR que transforma documentos en markdown estructurado - LLM, Foundation Model