Tipo: Repositorio GitHub Enlace original: https://github.com/neuml/paperetl Fecha de publicación: 2025-09-04
Resumen #
QUÉ #
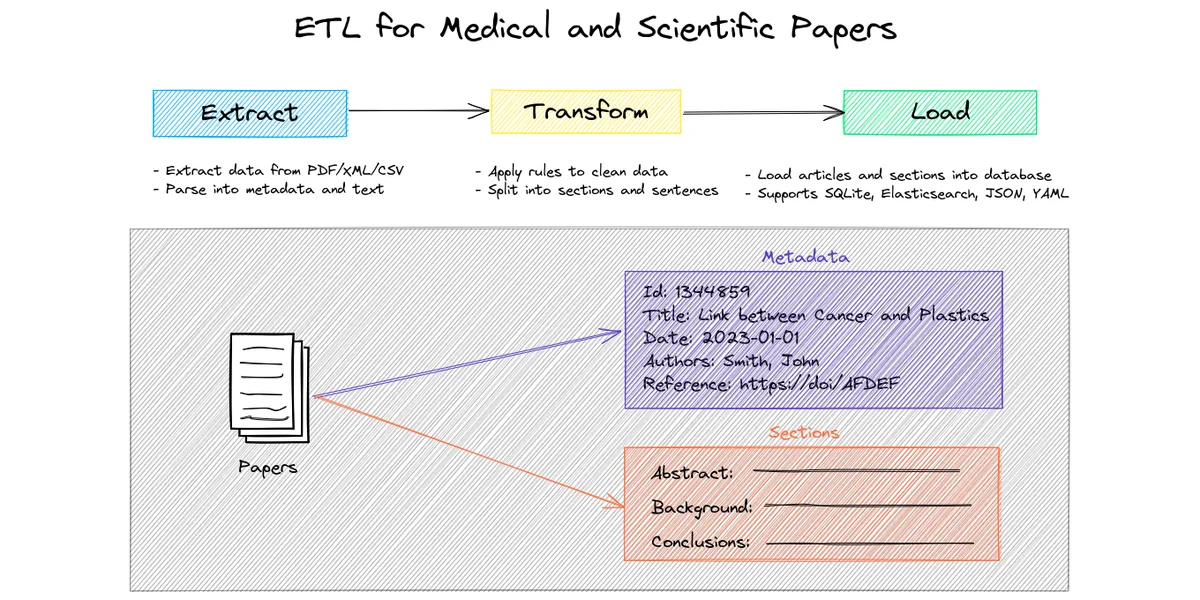
PaperETL es una librería ETL (Extract, Transform, Load) para el procesamiento de artículos médicos y científicos. Soporta varios formatos de entrada (PDF, XML, CSV) y diferentes almacenes de datos (SQLite, JSON, YAML, Elasticsearch).
POR QUÉ #
PaperETL es relevante para el negocio de IA porque automatiza la extracción y transformación de datos científicos, facilitando el análisis e integración de información crítica para la investigación y desarrollo. Resuelve el problema de la gestión y estandarización de datos heterogéneos provenientes de diversas fuentes académicas.
QUIÉN #
Los actores principales son la comunidad de código abierto y los desarrolladores que contribuyen al proyecto en GitHub. No hay competidores directos, pero existen otras soluciones ETL genéricas que podrían ser adaptadas para propósitos similares.
DÓNDE #
PaperETL se posiciona en el mercado de soluciones ETL especializadas para la gestión de datos científicos y médicos. Es parte del ecosistema de IA que apoya la investigación y el análisis de datos académicos.
CUÁNDO #
PaperETL es un proyecto relativamente nuevo pero en rápida evolución. Su madurez está en fase de crecimiento, con actualizaciones frecuentes y una comunidad activa.
IMPACTO EN EL NEGOCIO #
- Oportunidades: Integración con nuestro stack para automatizar la extracción y transformación de datos científicos, mejorando la calidad y velocidad de los análisis.
- Riesgos: Dependencia de una instancia local de GROBID para el análisis de PDF, lo que podría representar un cuello de botella.
- Integración: Posible integración con sistemas de gestión de datos existentes para enriquecer el conjunto de datos de investigación y desarrollo.
RESUMEN TÉCNICO #
- Tecnología principal: Python, SQLite, JSON, YAML, Elasticsearch, GROBID.
- Escalabilidad: Buena escalabilidad para pequeños y medianos conjuntos de datos, pero podría requerir optimizaciones para grandes volúmenes de datos.
- Diferenciadores técnicos: Soporte para varios formatos de entrada y almacenes de datos, integración con Elasticsearch para la búsqueda de texto completo.
Casos de uso #
- Private AI Stack: Integración en pipelines propietarias
- Soluciones para clientes: Implementación para proyectos de clientes
- Aceleración del desarrollo: Reducción del tiempo de comercialización de proyectos
- Inteligencia estratégica: Entrada para la hoja de ruta tecnológica
- Análisis competitivo: Monitoreo del ecosistema de IA
Recursos #
Enlaces Originales #
- paperetl - Enlace original
Artículo recomendado y seleccionado por el equipo Human Technology eXcellence elaborado mediante inteligencia artificial (en este caso con LLM HTX-EU-Mistral3.1Small) el 2025-09-04 19:15 Fuente original: https://github.com/neuml/paperetl
Artículos Relacionados #
- LangExtract se traduce como “Extracción de Lenguaje”. - Python, LLM, Open Source
- SurfSense se traduce como “Sentido de Surf” o “Detección de Surf” en español. - Open Source, Python
- Elysia: Marco de Agencia Impulsado por Árboles de Decisión - Best Practices, Python, AI Agent