Typ: Web Article Original Link: https://verdik.substack.com/p/how-to-get-consistent-classification Veröffentlichungsdatum: 2025-10-23
Autor: Verdi
Zusammenfassung #
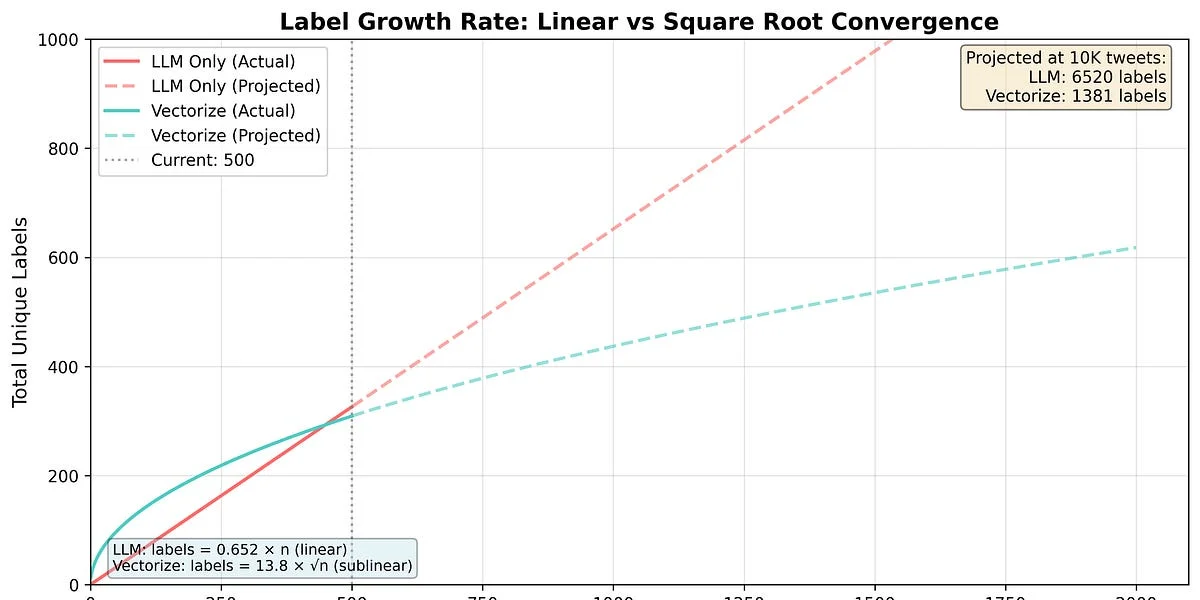
WAS - Dieser Artikel beschreibt eine Technik, um konsistente Klassifikationen aus großen Sprachmodellen (LLM) zu erhalten, die intrinsisch stochastisch sind. Der Autor stellt eine Methode zur Bestimmung konsistenter Etiketten unter Verwendung von Vektorembeddings und Vektorabfrage vor, mit einer in Golang implementierten Benchmark.
WARUM - Es ist für das AI-Geschäft relevant, weil es das Problem der Variabilität der von LLM generierten Etiketten angeht und die Konsistenz und Effizienz bei der Klassifizierung großer Mengen unmarkierter Daten verbessert.
WER - Der Autor ist Verdi, ein Experte für maschinelles Lernen. Die Hauptakteure umfassen ML-Entwickler, Unternehmen, die LLM für die Datenmarkierung verwenden, und die AI-Forschungsgemeinschaft.
WO - Es positioniert sich im Markt der AI-Lösungen für die Datenmarkierung und bietet eine Alternative zu den APIs der großen Modellanbieter.
WANN - Die Technik ist aktuell und entspricht einem sich entwickelnden Bedarf im Kontext der weit verbreiteten Nutzung von LLM für die Datenmarkierung. Die Reife der Lösung wird durch Benchmarks und praktische Implementierungen demonstriert.
GESCHÄFTLICHE AUSWIRKUNGEN:
- Chancen: Die Implementierung dieser Technik kann die Kosten senken und die Konsistenz bei der Datenmarkierung verbessern, wodurch der Prozess des Trainings von Machine-Learning-Modellen effizienter wird.
- Risiken: Die Abhängigkeit von Drittanbieter-APIs für die Markierung könnte gemildert werden, aber es ist eine Investition in die Infrastruktur für die Verwaltung von Vektorembeddings erforderlich.
- Integration: Die Technik kann in den bestehenden Stack integriert werden, indem Pinecone für die Vektorabfrage und Embeddings verwendet wird, die von Modellen wie GPT-3.5 generiert werden.
TECHNISCHE ZUSAMMENFASSUNG:
- Kern-Technologie-Stack: Golang für die Implementierung, GPT-3.5 für die Etikettengenerierung, voyage-.-lite für das Embedding (Größe 768), Pinecone für die Vektorabfrage.
- Skalierbarkeit und architektonische Grenzen: Die Lösung ist skalierbar, erfordert jedoch Rechenressourcen für die Verwaltung von Vektorembeddings und Vektorabfrage. Die Hauptgrenzen sind mit der anfänglichen Latenz und den Setup-Kosten verbunden.
- Wichtige technische Differenzierer: Verwendung von Vektorembeddings zur Clusterung inkonsistenter Etiketten, Vektorabfrage zur Suche nach ähnlichen Etiketten und Pfadkompression zur Gewährleistung der Konsistenz der Etiketten.
Anwendungsfälle #
- Private AI Stack: Integration in proprietäre Pipelines
- Client Solutions: Implementierung für Kundenprojekte
- Strategische Intelligenz: Input für technologische Roadmaps
- Wettbewerbsanalyse: Überwachung des AI-Ökosystems
Ressourcen #
Original Links #
- How to Get Consistent Classification From Inconsistent LLMs? - Original Link
Artikel empfohlen und ausgewählt vom Human Technology eXcellence Team, erstellt mit KI (in diesem Fall mit LLM HTX-EU-Mistral3.1Small) am 2025-10-23 13:57 Quelle: https://verdik.substack.com/p/how-to-get-consistent-classification