Type: GitHub Repository
Original link: https://github.com/rasbt/LLMs-from-scratch
Date de publication: 2025-09-04
Résumé #
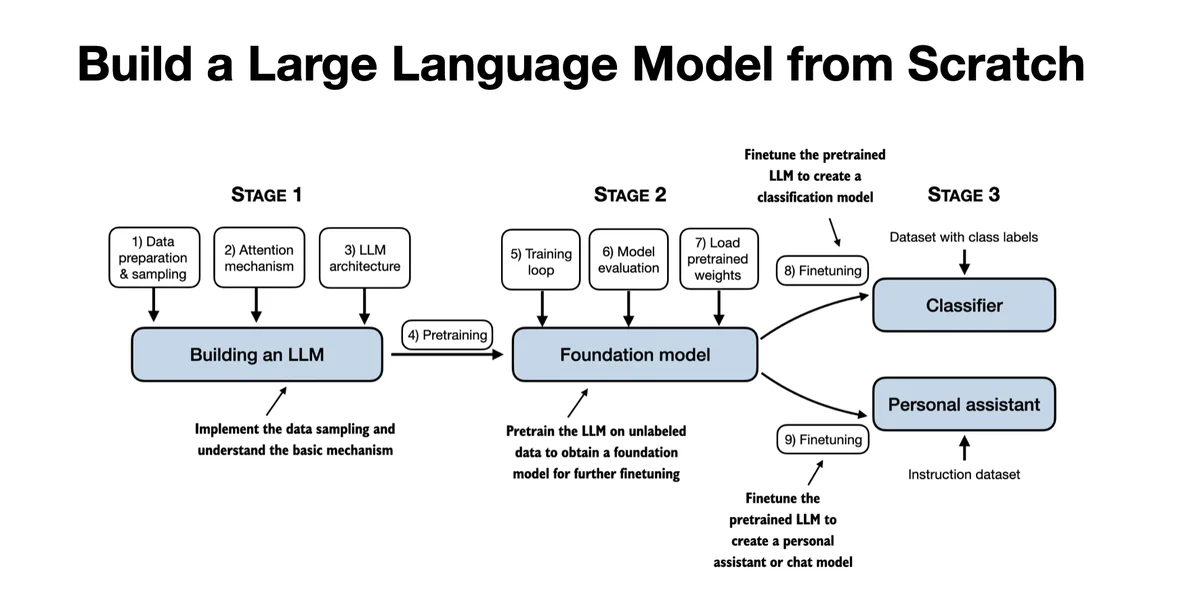
QUOI - Il s’agit d’un dépôt GitHub contenant le code pour développer, pré-entraîner et ajuster finement un modèle de langage de grande taille (LLM) similaire à ChatGPT, écrit en PyTorch. Il s’agit du code officiel pour le livre “Build a Large Language Model (From Scratch)” de Manning.
POURQUOI - Il est pertinent pour le secteur de l’IA car il fournit un guide détaillé et pratique pour construire et comprendre les LLM, permettant de répliquer et d’adapter des techniques avancées de traitement du langage naturel. Cela peut accélérer le développement de modèles personnalisés et améliorer les compétences internes.
QUI - Les principaux acteurs sont Sebastian Raschka (auteur du livre et du dépôt), Manning Publications (éditeur du livre), et la communauté des développeurs sur GitHub qui contribue et utilise le dépôt.
OÙ - Il se positionne sur le marché de l’éducation et du développement des LLM, offrant des ressources pratiques pour ceux qui souhaitent construire des modèles de langage avancés. Il fait partie de l’écosystème PyTorch et s’adresse aux développeurs et chercheurs intéressés par les LLM.
QUAND - Le dépôt est actif et en constante évolution, avec des mises à jour régulières. Il s’agit d’un projet consolidé mais en croissance, reflétant les tendances actuelles dans le développement des LLM.
IMPACT COMMERCIAL:
- Opportunités: Accélérer le développement de modèles de langage personnalisés, améliorer les compétences internes, et réduire les coûts de formation.
- Risques: Dépendance à un seul dépôt pour la formation, risque d’obsolescence si non mis à jour régulièrement.
- Intégration: Peut être intégré dans la pile de développement AI existante, en utilisant PyTorch et d’autres technologies mentionnées dans le dépôt.
RÉSUMÉ TECHNIQUE:
- Technologies principales: PyTorch, Python, Jupyter Notebooks, et divers frameworks de traitement du langage naturel.
- Scalabilité: Le dépôt est conçu pour l’éducation et la prototypage, pas pour la scalabilité industrielle. Cependant, les techniques peuvent être mises à l’échelle en utilisant des infrastructures cloud.
- Différenciateurs techniques: Implémentation détaillée des mécanismes d’attention, de pré-entraînement et d’ajustement fin, avec des exemples pratiques et des solutions aux exercices.
Cas d’utilisation #
- Stack AI Privé: Intégration dans des pipelines propriétaires
- Solutions Client: Implémentation pour des projets clients
- Accélération du Développement: Réduction du time-to-market des projets
- Intelligence Stratégique: Input pour la roadmap technologique
- Analyse Concurrentielle: Surveillance de l’écosystème AI
Feedback de tiers #
Feedback de la communauté: Les utilisateurs apprécient les ressources partagées pour construire et comprendre les modèles de langage, avec un consensus général sur l’utilité des guides et des implémentations. Les principales préoccupations concernent la complexité et l’accessibilité des techniques d’ajustement fin, avec des demandes de tutoriels supplémentaires spécifiques pour des tâches de traitement du langage naturel.
Ressources #
Liens Originaux #
- Build a Large Language Model (From Scratch) - Lien original
Article recommandé et sélectionné par l’équipe Human Technology eXcellence élaboré via intelligence artificielle (dans ce cas avec LLM HTX-EU-Mistral3.1Small) le 2025-09-04 19:22 Source originale: https://github.com/rasbt/LLMs-from-scratch
Articles Correlés #
- AI Engineering Hub - Open Source, AI, LLM
- Introducing Qwen3-Max-Preview (Instruct) - AI, Foundation Model
- Token & Token Usage | DeepSeek API Docs - Natural Language Processing, Foundation Model
Le Point de Vue HTX #
Ce sujet est au cœur de ce que nous construisons chez HTX. La technologie présentée ici — qu’il s’agisse d’agents IA, de modèles de langage ou de traitement de documents — représente exactement le type de capacités dont les entreprises européennes ont besoin, mais déployées selon leurs propres conditions.
Le défi n’est pas de savoir si cette technologie fonctionne. Elle fonctionne. Le défi est de la déployer sans envoyer les données de votre entreprise vers des serveurs américains, sans violer le RGPD et sans créer des dépendances fournisseur dont vous ne pouvez pas sortir.
C’est pourquoi nous avons créé ORCA — un chatbot d’entreprise privé qui apporte ces capacités à votre infrastructure. Même puissance que ChatGPT, mais vos données ne quittent jamais votre périmètre.
Vous voulez savoir si votre entreprise est prête pour l’IA ? Faites notre évaluation gratuite — 5 minutes, rapport personnalisé, feuille de route actionnable.
Articles Connexes #
- Une mise en œuvre étape par étape de l’architecture Qwen 3 MoE à partir de zéro - Open Source
- Agents d’IA pour les débutants - Un cours - AI Agent, Open Source, AI
- Présentation de Qwen3-Max-Preview (Instruct) - AI, Foundation Model
FAQ
Les grands modèles de langage peuvent-ils fonctionner sur une infrastructure privée ?
Oui. Les modèles open source comme LLaMA, Mistral, DeepSeek et Qwen peuvent fonctionner on-premise ou sur un cloud européen. Ces modèles atteignent des performances comparables à GPT-4 pour la plupart des tâches métier, avec l'avantage d'une souveraineté complète sur les données.
Quel LLM est le meilleur pour un usage professionnel ?
Le meilleur modèle dépend de votre cas d'usage. Pour l'analyse de documents et le chat, Mistral et LLaMA excellent. Pour l'analyse de données, DeepSeek offre un raisonnement solide. L'approche de HTX est agnostique : ORCA supporte plusieurs modèles.