Tipo: Web Article
Link originale: https://www.nature.com/articles/s41586-025-09422-z
Data pubblicazione: 2025-02-14
Sintesi #
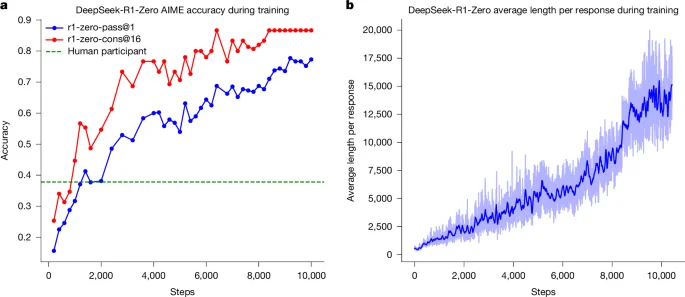
WHAT - L’articolo di Nature descrive DeepSeek-R1, un modello di AI che utilizza il reinforcement learning (RL) per migliorare le capacità di ragionamento dei Large Language Models (LLMs). Questo approccio elimina la necessità di dimostrazioni annotate da umani, permettendo ai modelli di sviluppare pattern di ragionamento avanzati come l’auto-riflessione e l’adattamento dinamico delle strategie.
WHY - È rilevante perché supera i limiti delle tecniche tradizionali basate su dimostrazioni umane, offrendo prestazioni superiori in compiti verificabili come matematica, programmazione e STEM. Questo può portare a modelli più autonomi e performanti.
WHO - Gli attori principali includono i ricercatori che hanno sviluppato DeepSeek-R1 e la comunità scientifica che studia e implementa modelli di AI avanzati. La community di GitHub è attiva nel discutere e migliorare il modello.
WHERE - Si posiziona nel mercato delle AI avanzate, specificamente nel settore dei Large Language Models e del reinforcement learning. È parte dell’ecosistema di ricerca e sviluppo di modelli di intelligenza artificiale.
WHEN - L’articolo è stato pubblicato nel febbraio 2025, indicando che DeepSeek-R1 è un modello relativamente nuovo ma già consolidato nella ricerca accademica.
BUSINESS IMPACT:
- Opportunità: Integrazione di DeepSeek-R1 per migliorare le capacità di ragionamento dei modelli esistenti, offrendo soluzioni più autonome e performanti.
- Rischi: Competizione con modelli che utilizzano tecniche di RL avanzate, potenziale necessità di investimenti in ricerca e sviluppo per mantenere la competitività.
- Integrazione: Possibile integrazione con lo stack esistente per migliorare le capacità di ragionamento dei modelli di AI aziendali.
TECHNICAL SUMMARY:
- Core technology stack: Python, Go, framework di machine learning, neural networks, algoritmi di RL.
- Scalabilità: Il modello può essere scalato per migliorare le capacità di ragionamento, ma richiede risorse computazionali significative.
- Differenziatori tecnici: Utilizzo di Group Relative Policy Optimization (GRPO) e bypass della fase di fine-tuning supervisionato, permettendo un’esplorazione più libera e autonoma del modello.
Casi d’uso #
- Private AI Stack: Integrazione in pipeline proprietarie
- Client Solutions: Implementazione per progetti clienti
- Development Acceleration: Riduzione time-to-market progetti
Feedback da terzi #
Community feedback: Gli utenti apprezzano DeepSeek-R1 per la sua capacità di ragionamento, ma esprimono preoccupazioni su problemi come la ripetizione e la leggibilità. Alcuni suggeriscono di utilizzare versioni quantizzate per migliorare l’efficienza e propongono di integrare dati di cold-start per migliorare le prestazioni.
Risorse #
Link Originali #
Articolo segnalato e selezionato dal team Human Technology eXcellence elaborato tramite intelligenza artificiale (in questo caso con LLM HTX-EU-Mistral3.1Small) il 2025-09-18 15:08 Fonte originale: https://www.nature.com/articles/s41586-025-09422-z