Type: GitHub Repository
Original link: https://github.com/neuml/paperetl
Date de publication: 2025-09-04
Résumé #
QUOI #
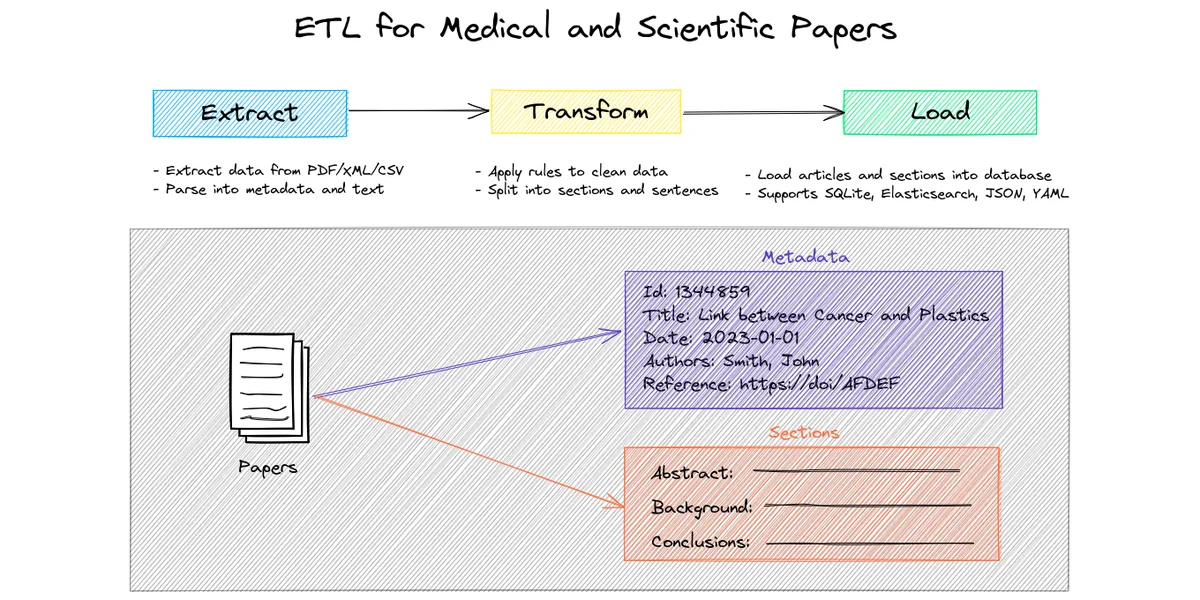
PaperETL est une bibliothèque ETL (Extract, Transform, Load) pour le traitement d’articles médicaux et scientifiques. Elle prend en charge divers formats d’entrée (PDF, XML, CSV) et différents datastores (SQLite, JSON, YAML, Elasticsearch).
POURQUOI #
PaperETL est pertinent pour le business AI car elle automatise l’extraction et la transformation de données scientifiques, facilitant l’analyse et l’intégration d’informations critiques pour la recherche et le développement. Elle résout le problème de gestion et de standardisation de données hétérogènes provenant de diverses sources académiques.
QUI #
Les principaux acteurs sont la communauté open-source et les développeurs qui contribuent au projet sur GitHub. Il n’y a pas de concurrents directs, mais il existe d’autres solutions ETL génériques qui pourraient être adaptées à des fins similaires.
OÙ #
PaperETL se positionne sur le marché des solutions ETL spécialisées dans la gestion de données scientifiques et médicales. Elle fait partie de l’écosystème AI qui soutient la recherche et l’analyse de données académiques.
QUAND #
PaperETL est un projet relativement nouveau mais en rapide évolution. Sa maturité est en phase de croissance, avec des mises à jour fréquentes et une communauté active.
IMPACT COMMERCIAL #
- Opportunités: Intégration avec notre stack pour automatiser l’extraction et la transformation de données scientifiques, améliorant la qualité et la vitesse des analyses.
- Risques: Dépendance d’une instance locale de GROBID pour le parsing des PDF, ce qui pourrait représenter un goulot d’étranglement.
- Intégration: Intégration possible avec les systèmes de gestion de données existants pour enrichir le dataset de recherche et développement.
RÉSUMÉ TECHNIQUE #
- Technologies principales: Python, SQLite, JSON, YAML, Elasticsearch, GROBID.
- Scalabilité: Bonne scalabilité pour les petits et moyens datasets, mais pourrait nécessiter des optimisations pour de grands volumes de données.
- Différenciateurs techniques: Support pour divers formats d’entrée et datastores, intégration avec Elasticsearch pour la recherche full-text.
Cas d’utilisation #
- Private AI Stack: Intégration dans des pipelines propriétaires
- Client Solutions: Mise en œuvre pour des projets clients
- Accélération du développement: Réduction du time-to-market des projets
- Intelligence stratégique: Input pour la roadmap technologique
- Analyse concurrentielle: Surveillance de l’écosystème AI
Ressources #
Liens originaux #
- paperetl - Lien original
Article recommandé et sélectionné par l’équipe Human Technology eXcellence élaboré via l’intelligence artificielle (dans ce cas avec LLM HTX-EU-Mistral3.1Small) le 2025-09-04 19:15 Source originale: https://github.com/neuml/paperetl
Articles connexes #
- Elysia: Framework Agentic Alimenté par des Arbres de Décision - Best Practices, Python, AI Agent
- SurfSense - Open Source, Python
- LangExtract - Python, LLM, Open Source
Articles Connexes #
- Elysia : Cadre agentique alimenté par des arbres de décision - Best Practices, Python, AI Agent
- Le cadre de travail de l’équipe rouge pour les LLM - Open Source, Python, LLM
- Couche humaine - Best Practices, AI, LLM