Type: Article Web
Lien original: https://www.nature.com/articles/s41586-025-09422-z
Date de publication: 2025-02-14
Résumé #
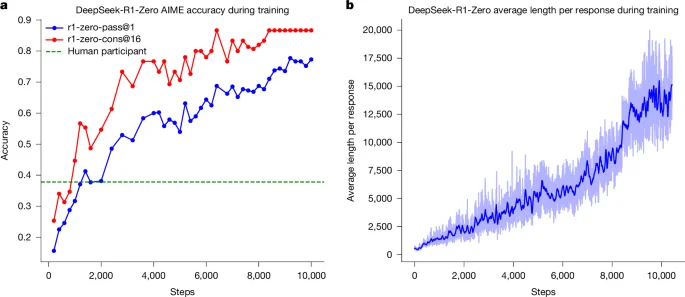
QUOI - L’article de Nature décrit DeepSeek-R1, un modèle d’IA qui utilise l’apprentissage par renforcement (RL) pour améliorer les capacités de raisonnement des Large Language Models (LLMs). Cette approche élimine la nécessité de démonstrations annotées par des humains, permettant aux modèles de développer des schémas de raisonnement avancés comme l’auto-réflexion et l’adaptation dynamique des stratégies.
POURQUOI - Il est pertinent car il surmonte les limites des techniques traditionnelles basées sur des démonstrations humaines, offrant des performances supérieures dans des tâches vérifiables comme les mathématiques, la programmation et les STEM. Cela peut conduire à des modèles plus autonomes et performants.
QUI - Les principaux acteurs incluent les chercheurs qui ont développé DeepSeek-R1 et la communauté scientifique qui étudie et met en œuvre des modèles d’IA avancés. La communauté GitHub est active dans la discussion et l’amélioration du modèle.
OÙ - Il se positionne sur le marché des IA avancées, spécifiquement dans le secteur des Large Language Models et de l’apprentissage par renforcement. Il fait partie de l’écosystème de recherche et de développement des modèles d’intelligence artificielle.
QUAND - L’article a été publié en février 2025, indiquant que DeepSeek-R1 est un modèle relativement nouveau mais déjà consolidé dans la recherche académique.
IMPACT COMMERCIAL:
- Opportunités: Intégration de DeepSeek-R1 pour améliorer les capacités de raisonnement des modèles existants, offrant des solutions plus autonomes et performantes.
- Risques: Concurrence avec des modèles utilisant des techniques de RL avancées, besoin potentiel d’investissements en recherche et développement pour maintenir la compétitivité.
- Intégration: Intégration possible avec la pile existante pour améliorer les capacités de raisonnement des modèles d’IA d’entreprise.
RÉSUMÉ TECHNIQUE:
- Technologies principales: Python, Go, framework de machine learning, réseaux neuronaux, algorithmes de RL.
- Scalabilité: Le modèle peut être mis à l’échelle pour améliorer les capacités de raisonnement, mais nécessite des ressources informatiques significatives.
- Différenciateurs techniques: Utilisation de Group Relative Policy Optimization (GRPO) et contournement de la phase de fine-tuning supervisé, permettant une exploration plus libre et autonome du modèle.
Cas d’utilisation #
- Pile AI Privée: Intégration dans des pipelines propriétaires
- Solutions Client: Implémentation pour des projets clients
- Accélération du Développement: Réduction du time-to-market des projets
Feedback de tiers #
Feedback de la communauté: Les utilisateurs apprécient DeepSeek-R1 pour sa capacité de raisonnement, mais expriment des préoccupations concernant des problèmes comme la répétition et la lisibilité. Certains suggèrent d’utiliser des versions quantifiées pour améliorer l’efficacité et proposent d’intégrer des données de cold-start pour améliorer les performances.
Ressources #
Liens Originaux #
Article signalé et sélectionné par l’équipe Human Technology eXcellence élaboré par intelligence artificielle (dans ce cas avec LLM HTX-EU-Mistral3.1Small) le 2025-09-18 15:08 Source originale: https://www.nature.com/articles/s41586-025-09422-z
Articles Correlés #
- [2505.03335] Absolute Zero: Reinforced Self-play Reasoning with Zero Data - Tech
- [2505.03335v2] Absolute Zero: Reinforced Self-play Reasoning with Zero Data - Tech
- The Illusion of Thinking - AI
Articles Connexes #
- [2505.03335] Zéro absolu : Raisonnement par auto-apprentissage renforcé avec zéro donnée - Tech
- [2505.24864] ProRL : L’apprentissage par renforcement prolongé élargit les limites du raisonnement dans les grands modèles de langage - LLM, Foundation Model
- [2505.03335v2] Zéro absolu : Raisonnement par auto-apprentissage renforcé avec zéro donnée - Tech