Type: Dépôt GitHub
Lien original: https://github.com/FareedKhan-dev/qwen3-MoE-from-scratch
Date de publication: 2025-09-20
Résumé #
QUOI - Il s’agit d’un tutoriel qui guide à la construction d’un modèle Qwen 3 MoE (Mixture-of-Experts) à partir de zéro, en utilisant Jupyter Notebook. Le tutoriel est basé sur un article de Medium et inclut un dépôt GitHub avec du code et des ressources supplémentaires.
POURQUOI - Il est pertinent pour le secteur de l’IA car il fournit un guide pratique pour implémenter un modèle avancé de LLM (Large Language Model) qui peut être utilisé pour améliorer les capacités de traitement du langage naturel. Cela peut conduire à des solutions plus efficaces et spécialisées pour les applications d’IA.
QUI - Les principaux acteurs incluent Fareed Khan, auteur du tutoriel, et Alibaba, qui a développé le modèle Qwen 3. La communauté des développeurs et des chercheurs en IA est le public principal.
OÙ - Il se positionne sur le marché éducatif de l’IA, offrant des ressources pour le développement de modèles avancés de LLM. Il fait partie de l’écosystème des outils open-source pour l’IA.
QUAND - Le tutoriel a été publié en 2025, indiquant qu’il repose sur des technologies récentes et avancées. La maturité du contenu est liée à la diffusion et à l’adoption du modèle Qwen 3.
IMPACT COMMERCIAL:
- Opportunités: L’implémentation de modèles MoE peut améliorer l’efficacité et la spécialisation des solutions d’IA, offrant un avantage concurrentiel.
- Risques: La dépendance aux technologies open-source peut comporter des risques liés à la maintenance et à la mise à jour du code.
- Intégration: Le tutoriel peut être utilisé pour former l’équipe de développement interne, intégrant les connaissances acquises dans la pile technologique existante.
RÉSUMÉ TECHNIQUE:
- Technologies principales: Jupyter Notebook, Python, PyTorch, Hugging Face Hub, sentencepiece, tiktoken, torch, matplotlib, tokenizers, safetensors.
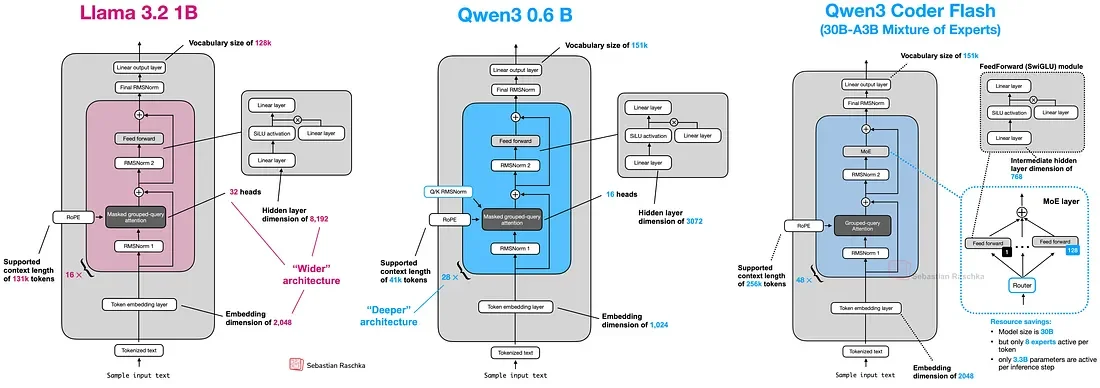
- Scalabilité et limites architecturales: Le modèle décrit a 0,8 milliard de paramètres, beaucoup moins que les 235 milliards du modèle original Qwen 3. Cela le rend plus gérable mais aussi moins puissant.
- Différenciateurs techniques clés: Utilisation de Mixture-of-Experts (MoE) pour activer seulement une partie des paramètres pour les requêtes, améliorant l’efficacité sans sacrifier les performances. Implémentation de techniques avancées comme Grouped-Query Attention (GQA) et RoPE (Rotary Position Embedding).
Cas d’utilisation #
- Stack AI Privé: Intégration dans des pipelines propriétaires
- Solutions Client: Implémentation pour des projets clients
- Accélération du Développement: Réduction du time-to-market des projets
- Intelligence Stratégique: Entrées pour la feuille de route technologique
- Analyse Concurrentielle: Surveillance de l’écosystème AI
Ressources #
Liens Originaux #
Article recommandé et sélectionné par l’équipe Human Technology eXcellence élaboré via l’intelligence artificielle (dans ce cas avec LLM HTX-EU-Mistral3.1Small) le 2025-09-23 16:51 Source originale: https://github.com/FareedKhan-dev/qwen3-MoE-from-scratch
Articles Correlés #
- Build a Large Language Model (From Scratch) - Foundation Model, LLM, Open Source
- Kimi K2: Open Agentic Intelligence - AI Agent, Foundation Model
- AI Engineering Hub - Open Source, AI, LLM
Articles Connexes #
- Présentation de Qwen3-Max-Preview (Instruct) - AI, Foundation Model
- Vous devriez écrire un agent · Le blogue de la mouche - AI Agent
- Hub d’ingénierie de l’IA - Open Source, AI, LLM