Type: Web Article Original link: https://verdik.substack.com/p/how-to-get-consistent-classification Publication date: 2025-10-23
Author: Verdi
Résumé #
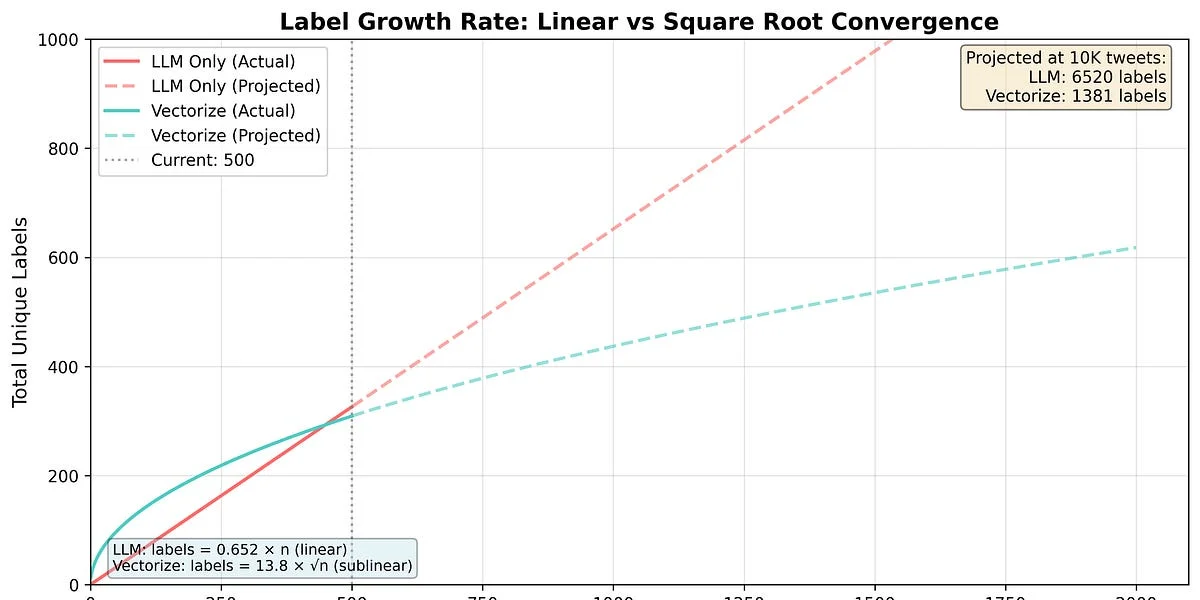
WHAT - Cet article décrit une technique pour obtenir des classifications cohérentes à partir de grands modèles linguistiques (LLM) qui sont intrinsèquement stochastiques. L’auteur présente une méthode pour déterminer des étiquettes cohérentes en utilisant des embeddings vectoriels et la recherche vectorielle, avec une implémentation benchmarkée en Golang.
WHY - C’est pertinent pour le business AI car il aborde le problème de la variabilité des étiquettes générées par les LLM, améliorant ainsi la cohérence et l’efficacité dans la classification de grands volumes de données non étiquetées.
WHO - L’auteur est Verdi, un expert en machine learning. Les principaux acteurs incluent les développeurs de ML, les entreprises utilisant les LLM pour l’étiquetage des données, et la communauté de recherche en IA.
WHERE - Il se positionne sur le marché des solutions AI pour l’étiquetage des données, offrant une méthode alternative par rapport aux API des grands fournisseurs de modèles.
WHEN - La technique est actuelle et répond à un besoin émergent dans le contexte de l’utilisation généralisée des LLM pour l’étiquetage des données. La maturité de la solution est démontrée par des benchmarks et des implémentations pratiques.
IMPACT COMMERCIAL:
- Opportunités: Mettre en œuvre cette technique peut réduire les coûts et améliorer la cohérence dans l’étiquetage des données, rendant le processus d’entraînement des modèles de machine learning plus efficace.
- Risques: La dépendance aux API de tiers pour l’étiquetage pourrait être atténuée, mais il est nécessaire d’investir dans une infrastructure pour la gestion des embeddings vectoriels.
- Intégration: La technique peut être intégrée dans la pile existante en utilisant Pinecone pour la recherche vectorielle et des embeddings générés par des modèles comme GPT-3.5.
RÉSUMÉ TECHNIQUE:
- Technologie principale: Golang pour l’implémentation, GPT-3.5 pour la génération d’étiquettes, voyage-.-lite pour l’embedding (dimension 768), Pinecone pour la recherche vectorielle.
- Scalabilité et limites architecturales: La solution est évolutive mais nécessite des ressources informatiques pour la gestion des embeddings vectoriels et de la recherche vectorielle. Les principales limites sont liées à la latence initiale et aux coûts de configuration.
- Différenciateurs techniques clés: Utilisation des embeddings vectoriels pour regrouper les étiquettes incohérentes, recherche vectorielle pour trouver des étiquettes similaires, et compression de chemin pour garantir la cohérence des étiquettes.
Cas d’utilisation #
- Private AI Stack: Intégration dans des pipelines propriétaires
- Client Solutions: Implémentation pour des projets clients
- Strategic Intelligence: Entrée pour la feuille de route technologique
- Competitive Analysis: Surveillance de l’écosystème AI
Ressources #
Liens Originaux #
- How to Get Consistent Classification From Inconsistent LLMs? - Lien original
Article signalé et sélectionné par l’équipe Human Technology eXcellence élaboré par intelligence artificielle (dans ce cas avec LLM HTX-EU-Mistral3.1Small) le 2025-10-23 13:57 Source originale: https://verdik.substack.com/p/how-to-get-consistent-classification
Articles Correlés #
- [2411.06037] Sufficient Context: A New Lens on Retrieval Augmented Generation Systems - Natural Language Processing
- The RAG Obituary: Killed by Agents, Buried by Context Windows - AI Agent, Natural Language Processing
- [2505.24863] AlphaOne: Reasoning Models Thinking Slow and Fast at Test Time - Foundation Model
Articles Connexes #
- L’Avis de Décès RAG : Tué par des Agents, Enterré par des Fenêtres de Contexte - AI Agent, Natural Language Processing
- Production RAG : ce que j’ai appris en traitant plus de 5 millions de documents - AI
- Les grands modèles de langage sont compétents pour résoudre et créer des tests d’intelligence émotionnelle | Psychologie de la communication - AI, LLM, Foundation Model