Tipo: Web Article
Link originale: https://verdik.substack.com/p/how-to-get-consistent-classification
Data pubblicazione: 2025-10-23
Autore: Verdi
Sintesi #
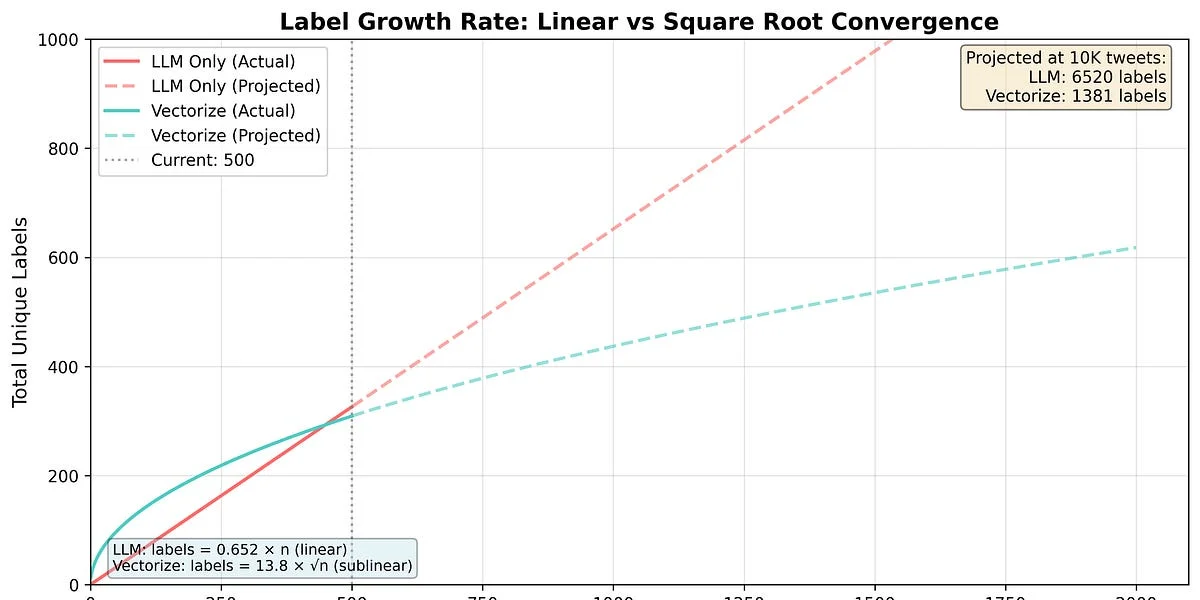
WHAT - Questo articolo descrive una tecnica per ottenere classificazioni coerenti da modelli linguistici di grandi dimensioni (LLM) che sono intrinsecamente stocastici. L’autore presenta un metodo per determinare etichette consistenti utilizzando embedding vettoriali e ricerca vettoriale, con un’implementazione benchmarked in Golang.
WHY - È rilevante per il business AI perché affronta il problema della variabilità delle etichette generate dai LLM, migliorando la coerenza e l’efficienza nella classificazione di grandi volumi di dati non etichettati.
WHO - L’autore è Verdi, un esperto di machine learning. Gli attori principali includono sviluppatori di ML, aziende che utilizzano LLM per il labeling di dati, e la community di ricerca in AI.
WHERE - Si posiziona nel mercato delle soluzioni AI per il labeling di dati, offrendo un metodo alternativo rispetto alle API dei grandi fornitori di modelli.
WHEN - La tecnica è attuale e risponde a una necessità emergente nel contesto dell’uso diffuso di LLM per il labeling di dati. La maturità della soluzione è dimostrata attraverso benchmark e implementazioni pratiche.
BUSINESS IMPACT:
- Opportunità: Implementare questa tecnica può ridurre i costi e migliorare la coerenza nel labeling di dati, rendendo più efficiente il processo di addestramento di modelli di machine learning.
- Rischi: La dipendenza da API di terze parti per il labeling potrebbe essere mitigata, ma è necessario investire in infrastruttura per la gestione di embedding vettoriali.
- Integrazione: La tecnica può essere integrata nello stack esistente utilizzando Pinecone per la ricerca vettoriale e embedding generati da modelli come GPT-3.5.
TECHNICAL SUMMARY:
- Core technology stack: Golang per l’implementazione, GPT-3.5 per la generazione di etichette, voyage-.-lite per l’embedding (dimensione 768), Pinecone per la ricerca vettoriale.
- Scalabilità e limiti architetturali: La soluzione è scalabile ma richiede risorse computazionali per la gestione di embedding vettoriali e ricerca vettoriale. I limiti principali sono legati alla latenza iniziale e ai costi di setup.
- Differenziatori tecnici chiave: Utilizzo di embedding vettoriali per clusterizzare etichette inconsistenti, ricerca vettoriale per trovare etichette simili, e path compression per garantire coerenza nelle etichette.
Casi d’uso #
- Private AI Stack: Integrazione in pipeline proprietarie
- Client Solutions: Implementazione per progetti clienti
- Strategic Intelligence: Input per roadmap tecnologica
- Competitive Analysis: Monitoring ecosystem AI
Risorse #
Link Originali #
- How to Get Consistent Classification From Inconsistent LLMs? - Link originale
Articolo segnalato e selezionato dal team Human Technology eXcellence elaborato tramite intelligenza artificiale (in questo caso con LLM HTX-EU-Mistral3.1Small) il 2025-10-23 13:57 Fonte originale: https://verdik.substack.com/p/how-to-get-consistent-classification
Il Punto di Vista HTX #
Questo tema è al centro di ciò che costruiamo in HTX. La tecnologia discussa qui — che si tratti di agenti AI, modelli linguistici o elaborazione documenti — rappresenta esattamente il tipo di capacità di cui le aziende europee hanno bisogno, ma implementata alle proprie condizioni.
La sfida non è se questa tecnologia funziona. Funziona. La sfida è implementarla senza inviare i dati aziendali a server USA, senza violare il GDPR e senza creare dipendenze da fornitori da cui non puoi uscire.
Per questo abbiamo costruito ORCA — un chatbot aziendale privato che porta queste capacità sulla tua infrastruttura. Stessa potenza di ChatGPT, ma i tuoi dati non escono mai dal tuo perimetro. Nessun costo per utente, nessuna fuga di dati, nessun problema di compliance.
Vuoi sapere quanto è pronta la tua azienda per l’AI? Fai il nostro Assessment gratuito della AI Readiness — 5 minuti, report personalizzato, roadmap operativa.
Articoli Correlati #
- The RAG Obituary: Killed by Agents, Buried by Context Windows - AI Agent, Natural Language Processing
- MCP is eating the world—and it’s here to stay - Natural Language Processing, AI, Foundation Model
- [2411.06037] Sufficient Context: A New Lens on Retrieval Augmented Generation Systems - Natural Language Processing
FAQ
I modelli linguistici di grandi dimensioni possono girare su infrastruttura privata?
Sì. Modelli open source come LLaMA, Mistral, DeepSeek e Qwen possono funzionare on-premise o su cloud europeo. Questi modelli raggiungono prestazioni paragonabili a GPT-4 per la maggior parte dei task aziendali, con il vantaggio della completa sovranità sui dati. Lo stack PRISMA di HTX è progettato per implementare questi modelli per le PMI europee.
Quale LLM è migliore per uso aziendale?
Il modello migliore dipende dal caso d'uso. Per analisi documenti e chat, modelli come Mistral e LLaMA eccellono. Per analisi dati, DeepSeek offre forte ragionamento. L'approccio di HTX è model-agnostic: ORCA supporta più modelli così puoi scegliere il più adatto senza vendor lock-in.