Tipo: X (Twitter) Post
Link originale: https://x.com/aliestaha/status/2030074784894308770?s=43&t=ANuJI-IuN5rdsaLueycEbA
Data pubblicazione: 2026-03-23
Sintesi #
Introduzione #
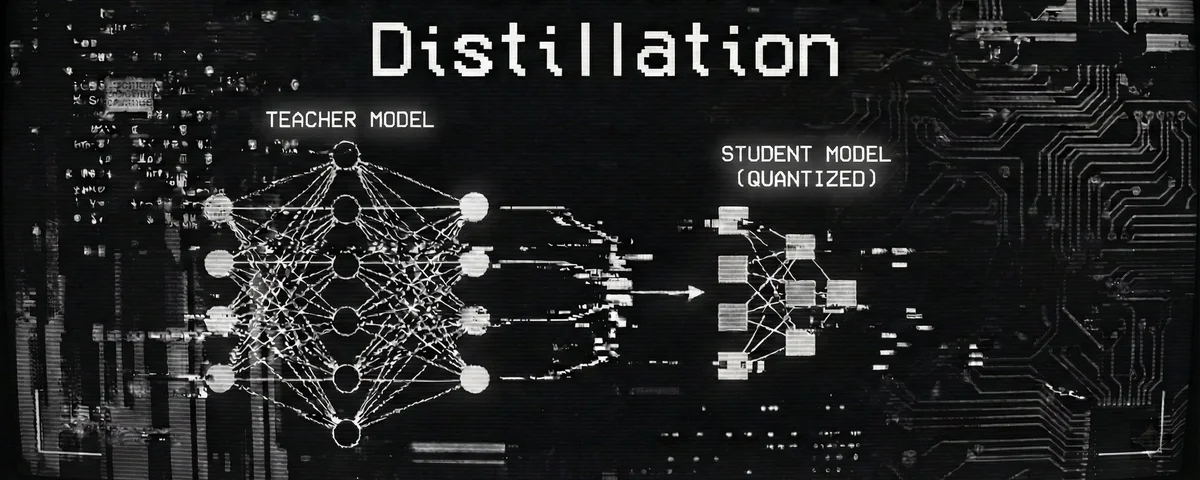
Hai mai pensato a come possiamo rendere i modelli di machine learning più efficienti senza sacrificare la loro precisione? Il post di Ali Estaha su “Distillation Training: 4 Bits” ha catturato la mia attenzione con la sua promessa di ottimizzazione. In un mondo dove ogni bit conta, ridurre la precisione dei pesi dei modelli da 32 bit a 4 bit potrebbe sembrare un azzardo, ma potrebbe anche essere la chiave per modelli più veloci e meno dispendiosi. Vediamo insieme perché questa idea merita la nostra attenzione e come potrebbe rivoluzionare il modo in cui addestriamo e utilizziamo i modelli di machine learning.
Il Contesto #
Il distillazione del modello è una tecnica che permette di creare modelli più leggeri e veloci partendo da modelli più grandi e complessi. L’idea è di trasferire il sapere di un modello insegnante a un modello studente, mantenendo alta la precisione ma riducendo la complessità. In questo caso, l’attenzione è rivolta alla quantizzazione dei pesi del modello, ovvero alla riduzione della precisione dei numeri che rappresentano i parametri del modello. Passare da 32 bit a 4 bit significa ridurre drasticamente la quantità di memoria necessaria e migliorare le prestazioni di calcolo.
Questa tecnica si inserisce in un contesto in cui l’efficienza dei modelli di machine learning è diventata cruciale. Con l’aumento della complessità dei modelli e la necessità di deploy su dispositivi con risorse limitate, trovare modi per ottimizzare i modelli è diventato una priorità. Ali Estaha, un esperto nel campo del machine learning, ha condiviso questa idea per stimolare la discussione e l’innovazione in questo ambito.
Perché È Interessante #
Efficienza e Prestazioni #
Ridurre la precisione dei pesi da 32 bit a 4 bit può sembrare un compromesso rischioso, ma i benefici potenziali sono enormi. Modelli più leggeri significano tempi di inferenza più rapidi e un consumo di memoria ridotto. Questo è particolarmente importante per applicazioni in tempo reale, come l’elaborazione di immagini in tempo reale o il riconoscimento vocale, dove ogni millisecondo conta.
Applicazioni Pratiche #
Un esempio concreto è l’uso di modelli di machine learning su dispositivi mobili. Immagina di avere un modello di riconoscimento facciale che può funzionare in tempo reale sul tuo smartphone senza drenare la batteria. Questo è possibile grazie alla quantizzazione dei pesi, che permette di eseguire il modello in modo più efficiente. Un altro esempio è l’uso di modelli di machine learning in ambienti embedded, dove le risorse di calcolo sono limitate. La quantizzazione permette di deployare modelli complessi su dispositivi con risorse limitate, aprendo nuove possibilità per l’Internet delle Cose (IoT).
Confronti con Alternative #
Rispetto ad altre tecniche di ottimizzazione, come la pruning (potatura) dei modelli, la quantizzazione offre un approccio più sistematico e meno invasivo. La pruning può portare a una riduzione significativa della dimensione del modello, ma può anche compromettere la precisione. La quantizzazione, invece, mantiene un alto livello di precisione pur riducendo la complessità del modello. Inoltre, la quantizzazione può essere applicata a modelli già addestrati, rendendola una soluzione flessibile e facile da implementare.
Come Funziona #
La quantizzazione dei pesi di un modello di machine learning è un processo che coinvolge diverse fasi. Innanzitutto, è necessario addestrare il modello con pesi a 32 bit per ottenere un modello di alta precisione. Successivamente, i pesi vengono quantizzati a 4 bit, riducendo la precisione ma mantenendo la struttura del modello. Questo processo può essere automatizzato utilizzando strumenti come TensorFlow Lite o PyTorch, che offrono supporto per la quantizzazione post-training.
Un esempio pratico potrebbe essere l’uso di TensorFlow Lite per quantizzare un modello di riconoscimento di immagini. Dopo aver addestrato il modello con pesi a 32 bit, è possibile utilizzare TensorFlow Lite per convertire il modello in una versione quantizzata a 4 bit. Questo processo può essere eseguito con poche righe di codice e non richiede una conoscenza approfondita della quantizzazione. Una volta quantizzato, il modello può essere deployato su dispositivi mobili o embedded, offrendo prestazioni migliorate e un consumo di memoria ridotto.
Riflessioni #
La quantizzazione dei pesi dei modelli di machine learning rappresenta una svolta significativa nel campo dell’ottimizzazione dei modelli. Con l’aumento della complessità dei modelli e la necessità di deploy su dispositivi con risorse limitate, trovare modi per rendere i modelli più efficienti è diventato cruciale. La tecnica di quantizzazione a 4 bit, come proposta da Ali Estaha, offre una soluzione promettente per migliorare le prestazioni dei modelli senza sacrificare la precisione.
In un futuro prossimo, possiamo aspettarci di vedere sempre più modelli di machine learning quantizzati, soprattutto in ambiti come l’Internet delle Cose e i dispositivi mobili. Questa tendenza potrebbe portare a una maggiore diffusione delle applicazioni di machine learning, rendendo la tecnologia accessibile a un pubblico più ampio. Inoltre, la quantizzazione potrebbe stimolare ulteriori ricerche nel campo dell’ottimizzazione dei modelli, portando a nuove tecniche e soluzioni innovative.
Casi d’uso #
- Private AI Stack: Integrazione in pipeline proprietarie
- Client Solutions: Implementazione per progetti clienti
Risorse #
Link Originali #
- Distillation Training : 4 Bits - Link originale
Articolo segnalato e selezionato dal team Human Technology eXcellence elaborato tramite intelligenza artificiale (in questo caso con LLM HTX-EU-Mistral3.1Small) il 2026-03-23 08:52 Fonte originale: https://x.com/aliestaha/status/2030074784894308770?s=43&t=ANuJI-IuN5rdsaLueycEbA
Articoli Correlati #
- I’ve been thinking a bit about continual learning recently, especially as it relates to long-running agents (and running a few toy experiments with MLX) - Machine Learning, Go, AI Agent
- Introduction to LLM Post-Training Techniques | PDF - AI, LLM, Machine Learning
- spent the entire day testing Qwopus (Claude 4 - Tech