Type: GitHub Repository Original link: https://github.com/neuml/paperetl Publication date: 2025-09-04
Summary #
WHAT #
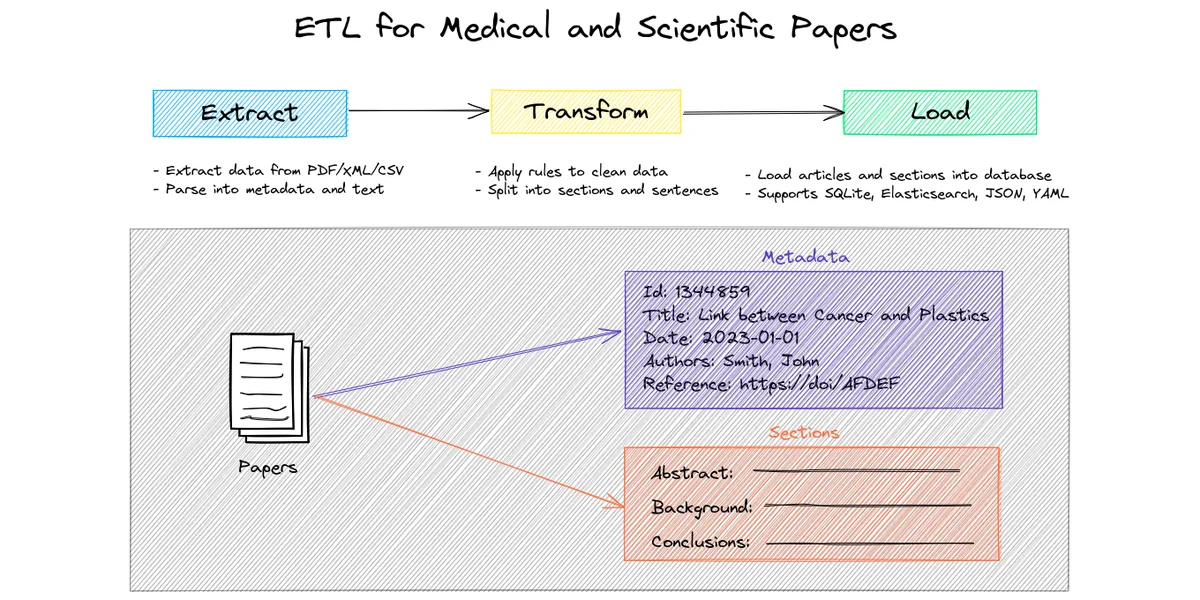
PaperETL is an ETL (Extract, Transform, Load) library for processing medical and scientific articles. It supports various input formats (PDF, XML, CSV) and different datastores (SQLite, JSON, YAML, Elasticsearch).
WHY #
PaperETL is relevant for the AI business because it automates the extraction and transformation of scientific data, facilitating the analysis and integration of critical information for research and development. It solves the problem of managing and standardizing heterogeneous data from various academic sources.
WHO #
The main actors are the open-source community and developers who contribute to the project on GitHub. There are no direct competitors, but there are other generic ETL solutions that could be adapted for similar purposes.
WHERE #
PaperETL positions itself in the market of ETL solutions specialized in managing scientific and medical data. It is part of the AI ecosystem that supports academic research and data analysis.
WHEN #
PaperETL is a relatively new but rapidly evolving project. Its maturity is in the growth phase, with frequent updates and an active community.
BUSINESS IMPACT #
- Opportunities: Integration with our stack to automate the extraction and transformation of scientific data, improving the quality and speed of analyses.
- Risks: Dependence on a local instance of GROBID for PDF parsing, which could represent a bottleneck.
- Integration: Possible integration with existing data management systems to enrich the research and development dataset.
TECHNICAL SUMMARY #
- Core technology stack: Python, SQLite, JSON, YAML, Elasticsearch, GROBID.
- Scalability: Good scalability for small and medium datasets, but may require optimizations for large volumes of data.
- Technical differentiators: Support for various input formats and datastores, integration with Elasticsearch for full-text search.
Use Cases #
- Private AI Stack: Integration into proprietary pipelines
- Client Solutions: Implementation for client projects
- Development Acceleration: Reduction of project time-to-market
- Strategic Intelligence: Input for technological roadmap
- Competitive Analysis: Monitoring AI ecosystem
Resources #
Original Links #
- paperetl - Original link
Article recommended and selected by the Human Technology eXcellence team, processed through artificial intelligence (in this case with LLM HTX-EU-Mistral3.1Small) on 2025-09-04 19:15 Original source: https://github.com/neuml/paperetl
Related Articles #
- Automatically annotate papers using LLMs - LLM, Open Source
- LangExtract - Python, LLM, Open Source
- Enterprise Deep Research - Python, Open Source